Project Darkbloom: Unlocking Idle Compute for AI
Project Darkbloom explores distributed AI inference on underused Macs, combining verified nodes, hardware-backed privacy, and better economics to turn idle Apple Silicon into a more efficient, privacy-first compute network.

AI inference is becoming one of the defining infrastructure layers of the internet. But today, most inference still runs through a centralized stack that is expensive, capacity-constrained, and layered with margin.
At the same time, millions of capable machines already exist in the world, and most of them sit idle for large portions of the day.
Project Darkbloom is an Eigen Labs research initiative exploring a simple but powerful idea: what if AI inference could run on underused Macs, with stronger privacy protections, better economics, and a more distributed supply of compute?
Rethinking the economics of inference
Today’s inference stack typically includes several layers between the user and the hardware doing the actual work. API providers add a product layer. Hyperscalers provide the underlying infrastructure. Hardware vendors capture value at the chip layer. Each part of that system serves a purpose, but it also creates a cost structure that makes inference more expensive than the underlying compute alone would suggest.
This model made sense for the first wave of large-scale AI deployment. But as inference demand grows, it is worth asking whether every workload needs to flow through the same centralized path.
Darkbloom starts from a different premise. Instead of assuming that new supply must come only from new data center buildout, it looks at the vast amount of compute that already exists and is already paid for.
Why Macs are an interesting place to start
Apple Silicon has quietly made modern Macs unusually capable inference machines. Unified memory, high memory bandwidth, Metal acceleration, and efficient power usage give these systems a profile that is well-suited to running useful models locally.
Just as important, these machines are underused.
A laptop might be actively used for a few hours each day and then remain idle overnight. Across the installed base, that adds up to a significant amount of dormant compute capacity. The hardware is already purchased. In many cases, the marginal cost of using it is primarily the cost of electricity.
Darkbloom explores what happens when that idle capacity is organized into a network.
What Darkbloom does
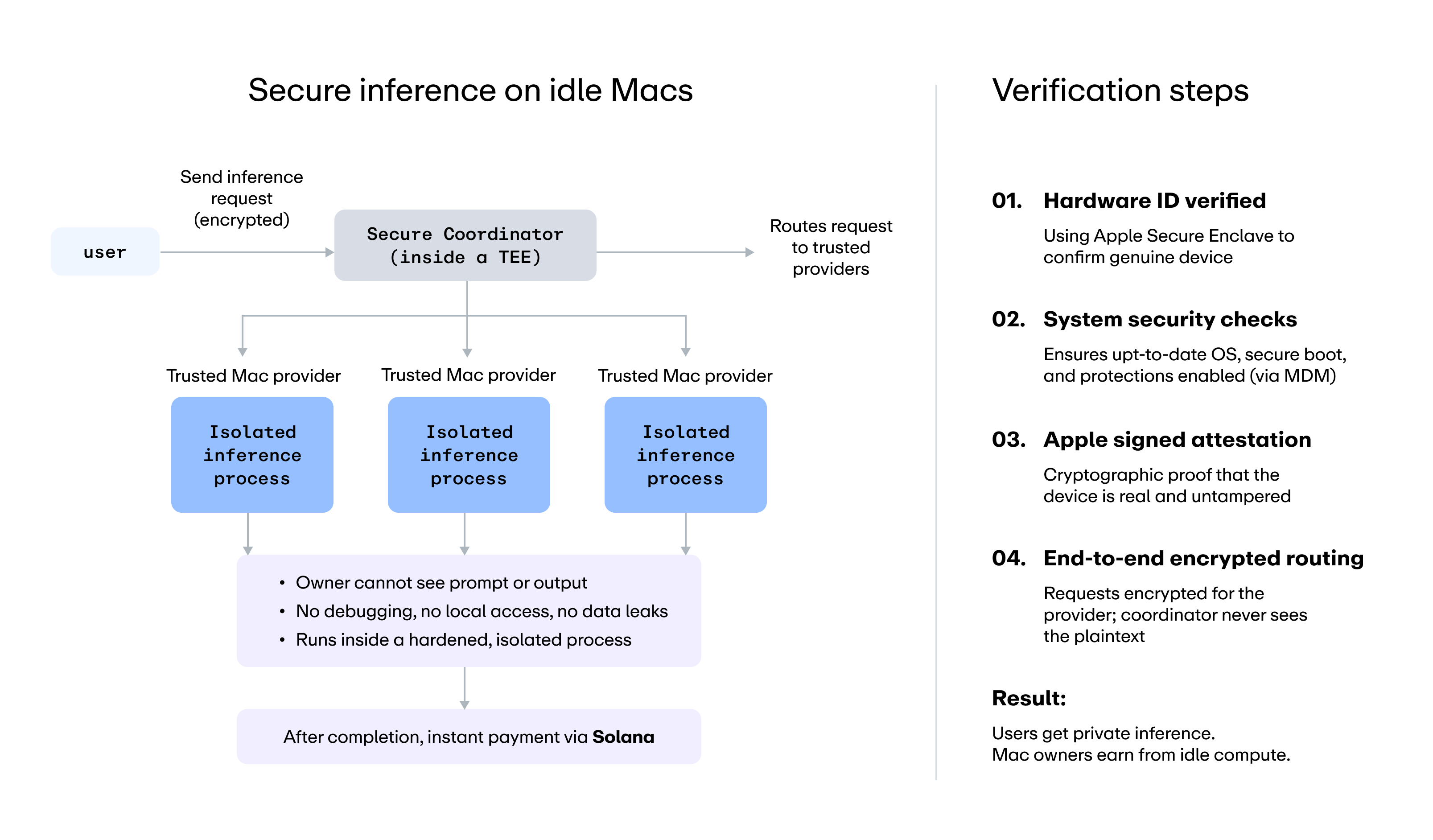
Darkbloom routes inference requests to verified Mac nodes that can serve them. The system includes a coordinator that matches supply and demand, a provider agent running on Mac hardware, and developer-facing interfaces designed to make experimentation straightforward, including an OpenAI-compatible API.
From the developer perspective, the goal is simplicity. Requests should be easy to send, easy to integrate, and easy to verify.
From the infrastructure perspective, the harder problem is trust.
If a request is processed on someone else’s machine, what keeps that machine operator from inspecting the prompt or interfering with the execution environment?
That question is central to the design.
A privacy-first approach to distributed inference
Darkbloom is built around a privacy-first model for distributed inference. The provider process is hardened against common local inspection paths, including debugger attachment and external memory inspection. The integrity of the running binary is also part of the trust model, helping ensure that the software serving requests matches what the network expects.
The system also uses hardware-backed attestation rooted in Apple’s security architecture. Secure Enclave keys, attestation signals, and recurring challenge-response checks are used to verify that a participating node is running with the expected protections and software state.
This is what Darkbloom means by verifiable privacy. The goal is not simply to claim that a node is trustworthy, but to create a system where trust can be checked against hardware-backed evidence.
It is also important to be precise about the current trust boundary. Today, the coordinator remains part of the trusted routing layer. That boundary is explicit. Darkbloom is designed to make its assumptions clear rather than obscuring them behind broad security language.
Building the real system, not just the demo
One of the clearest lessons from Project Darkbloom is that the hardest parts of a system like this are often not the obvious ones.
Getting a request to run on a Mac is only one part of the problem. In practice, the difficult work sits in code signing, packaging, release consistency, attestation, model lifecycle management, node availability, challenge timing, and failure handling.
When binary hashes are part of the security model, release engineering becomes security engineering. When nodes are continuously verified, timing and recovery edge cases become part of the core architecture. When the network is live, cold starts, disconnects, corrupted model files, and memory pressure are not exceptions. They are everyday operating realities.
That is one reason Darkbloom is being developed as a research initiative in the open. The goal is not only to prove that the system can work once, but to understand how it behaves under real operating conditions.
A different cost structure
The economics of this model are meaningfully different from centralized inference.
Darkbloom’s benchmark pricing showed that some models could be priced at roughly half the cost of major aggregators, not because of subsidy, but because of structure. In a traditional stack, costs include hardware, facilities, cooling, networking, operational overhead, and multiple layers of margin. In Darkbloom’s model, the hardware already exists and the marginal cost is driven largely by electricity. Providers keep 95% of revenue.
That creates a different set of possibilities:
For users, it can lower the cost of inference. For operators, it can turn idle machines into productive infrastructure. For the broader ecosystem, it offers a path toward a more distributed and capital-efficient compute layer.
Where Darkbloom is today
Darkbloom is now live in research preview. The system includes the coordinator, the hardened provider agent, Secure Enclave integration, operator tooling, a web console, and support across text, images, and speech-to-text. The paper is published, and the codebase is open-sourced.
This is still early work, and there are real questions left to answer. But that is exactly the point of releasing it as a research initiative.
Darkbloom is an exploration of what a more distributed, privacy-first, and economically efficient inference layer could look like in practice.
Why this matters
AI infrastructure will shape the next generation of software. The question is not only how much compute the world can build, but also how efficiently it can use the compute it already has.
There are already millions of capable machines sitting on desks around the world. Most of them are idle much of the time. If those machines can be organized into a usable network with credible privacy guarantees and better economics, the implications could extend far beyond a single project.
That is the direction Project Darkbloom is exploring.
Project Darkbloom is an Eigen Labs research initiative.