Introducing Verifiable Agents on EigenLayer
The “Level 1 Agent” is a standardized way for agents to integrate with verifiable tools by using AVSs.
Agents are a powerful new vector for personalizing users' interface with next-generation applications. In combination with crypto rails, agents become verifiable actors, giving their owners transparency and control over how the agents are used to augment the users' experience navigating the web.
The possibilities have captured the imagination of the world’s largest companies and spurred interest in OpenAI’s Operator, Anthropic’s Computer Use product, and frameworks like Eliza. They have also sparked a new wave of debate about how these agents and the models powering them can be held accountable for their assumptions and inferences.
Unlike those built on web2 rails, onchain agents can be autonomous, verifiable, and censorship-resistant. However, they also need to be practically cheap, something the onchain environment can’t provide even with improvements to underlying L1s and L2s.
AI software implemented as EigenLayer AVSs directly and elegantly addresses these limitations. In this post, we explore the following:
- What is an agent?
- What are onchain agents?
- How EigenLayer addresses the core challenge of running onchain agents
- How to start building a “Level 1” agent
What’s an Agent?
An “agent” is a central orchestrator that manages (in a closed loop) the entire operation a user wants performed in some environment. The more capable the agent is of reaching the goal, the more autonomous the agent. It can receive a user’s goal or task and decide how to proceed by consulting the Orchestrator, Model (LLM), Memory, and Tools.
Core Components
Thus, in its entirety, an agent is a composition of:
- Agent Runtime
- LLM
- Tools
- Orchestrator
- Memory / State
- Goal(s)
- Environment
Visually, this might look like the following architecture (diagram from Google’s Agent Whitepaper).
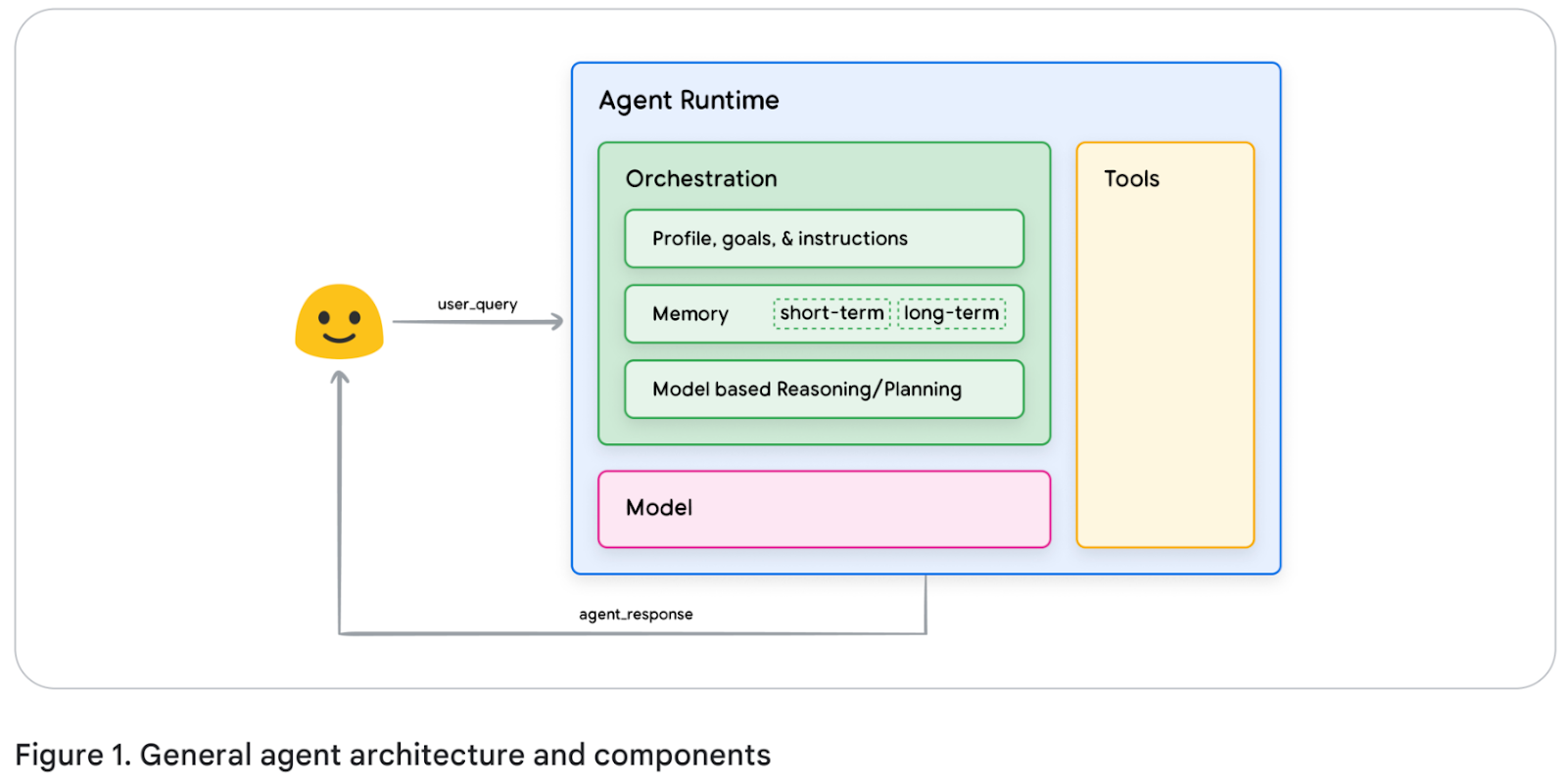
How Components Work Together
Much like a well-orchestrated team, each component of an agent plays a specific role while maintaining continuous communication with other parts to achieve the overall objective.
LLM Interface
The LLM is the agent's “brain” and is treated as if it has reasoning capabilities. LLMs like Claude, LlaMa, and the GPT series have different training data, and they can be swapped under the hood as better models are released. The agent deployer can, at runtime, specify whether a certain open-source LLM should be used or if it has the option to specify a closed-source model provider.
Tools
LLMs are self-contained and can only “reason” based on the data the model was trained on. To connect to live data and real-time information, agents rely on tools that can read and write information using APIs exposed as plugins or extensions by the agent framework.
Orchestrator
The orchestrator consults the LLM on how to proceed with the task step by step. This mechanism can be a part of the prompt or a separate module, often a framework (like Eliza) that acts as the “glue” between the rest of the components.
Note that depending on the sophistication of the LLM, a significant part of this orchestration function may be embedded in it. Directionally, this is the approach that Anthropic describes in its “Building Effective Agents” blog post, which sometimes involves multiple LLMs per agent.
Memory / State
This is a mix of short-term memory (the context provided in the current session), the results of outside tool calls, and, optionally, long-term memory to persist information across multiple invocations/sessions.
Execution Flow
Given these components, a high-level flow might be:
- Agent receives a high-level goal or user query.
- Agent consults Memory (context) and LLM (for analysis or explanation).
- Orchestrator decides the next Action (e.g., “call a specific Tool”).
- Agent uses that Action to invoke the Tool, possibly with parameters.
- Tool provides a result (e.g., an API response), which is stored in Memory.
- Agent (and Orchestrator) iterate until the goal is completed.
- Finally, Agent presents the outcome to the user.
Below is a sequence diagram of how an agent would use tool calling to serve a user prompt.
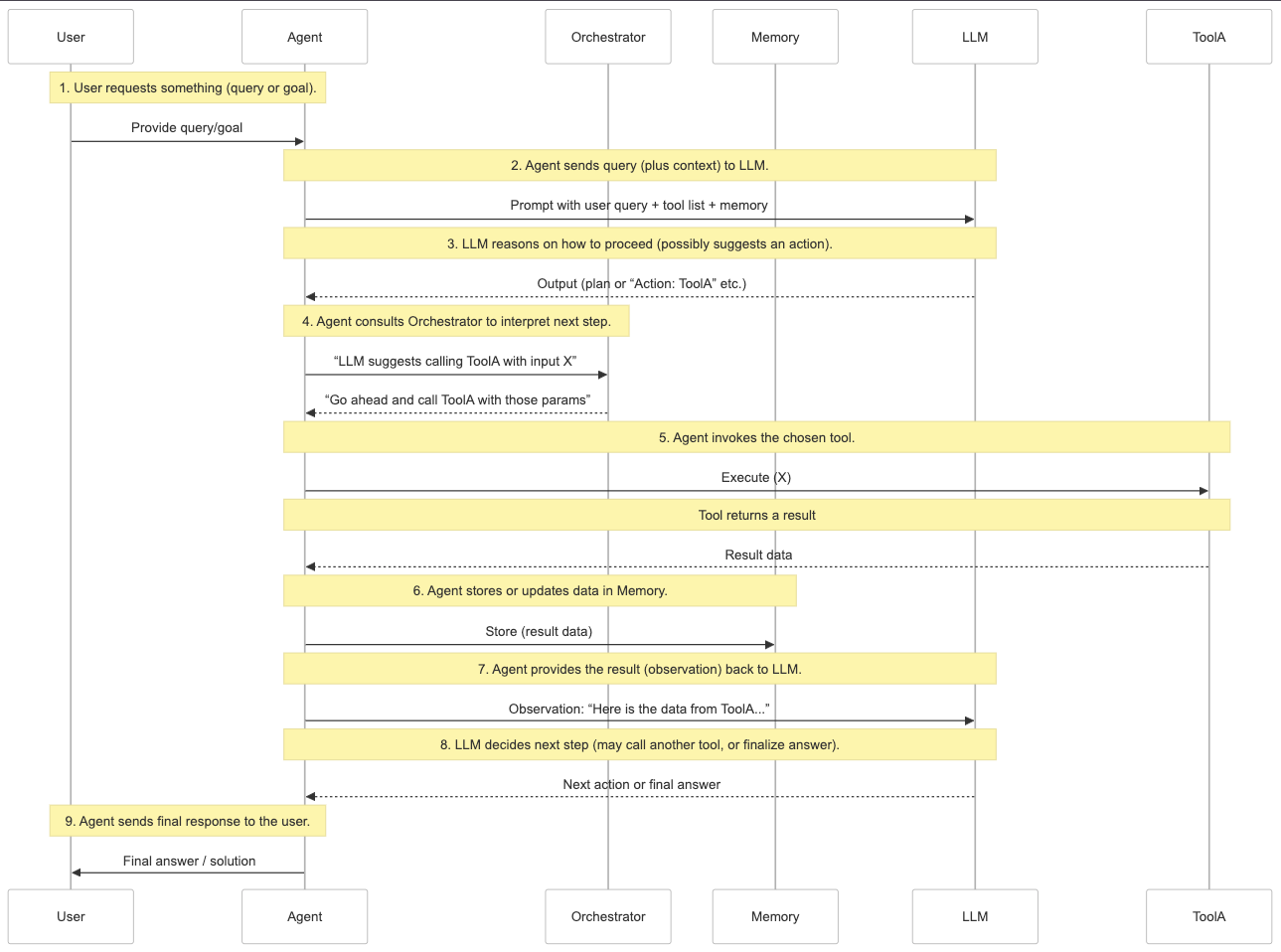
Key Implementation Considerations
- Tool Awareness: The LLM “knows” about ToolA, ToolB, etc., because the agent injects a description of these tools into the LLM prompt or context.
- Planning vs. Execution: Some systems/frameworks combine planning and execution in one step (the LLM itself decides). Like the diagram above, others have a separate Orchestrator to validate or interpret the LLM’s suggestions.
- Memory Updates: Storing intermediate results is crucial for multi-step tasks so the LLM can build on previous actions.
- Iterative Loop: The agent can call multiple tools in sequence before reaching a final answer, repeating steps 2–9 as needed.
Practical Example: Trip Planning
What would it look like if the agent was tasked with planning a weekend trip? A very simplified flow could look like this:
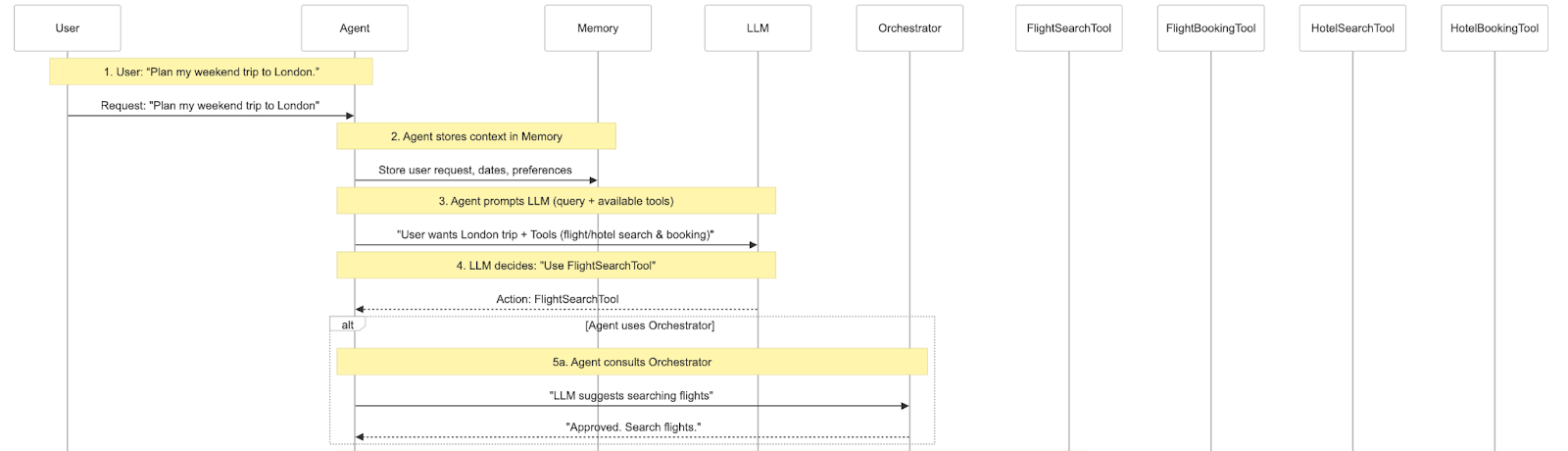
The full (zoomable) diagram can be seen here.
This example demonstrates how agents decompose complex tasks into manageable steps, coordinate multiple tools, and maintain context throughout the process.
Onchain Agents: Bringing Verifiability to AI
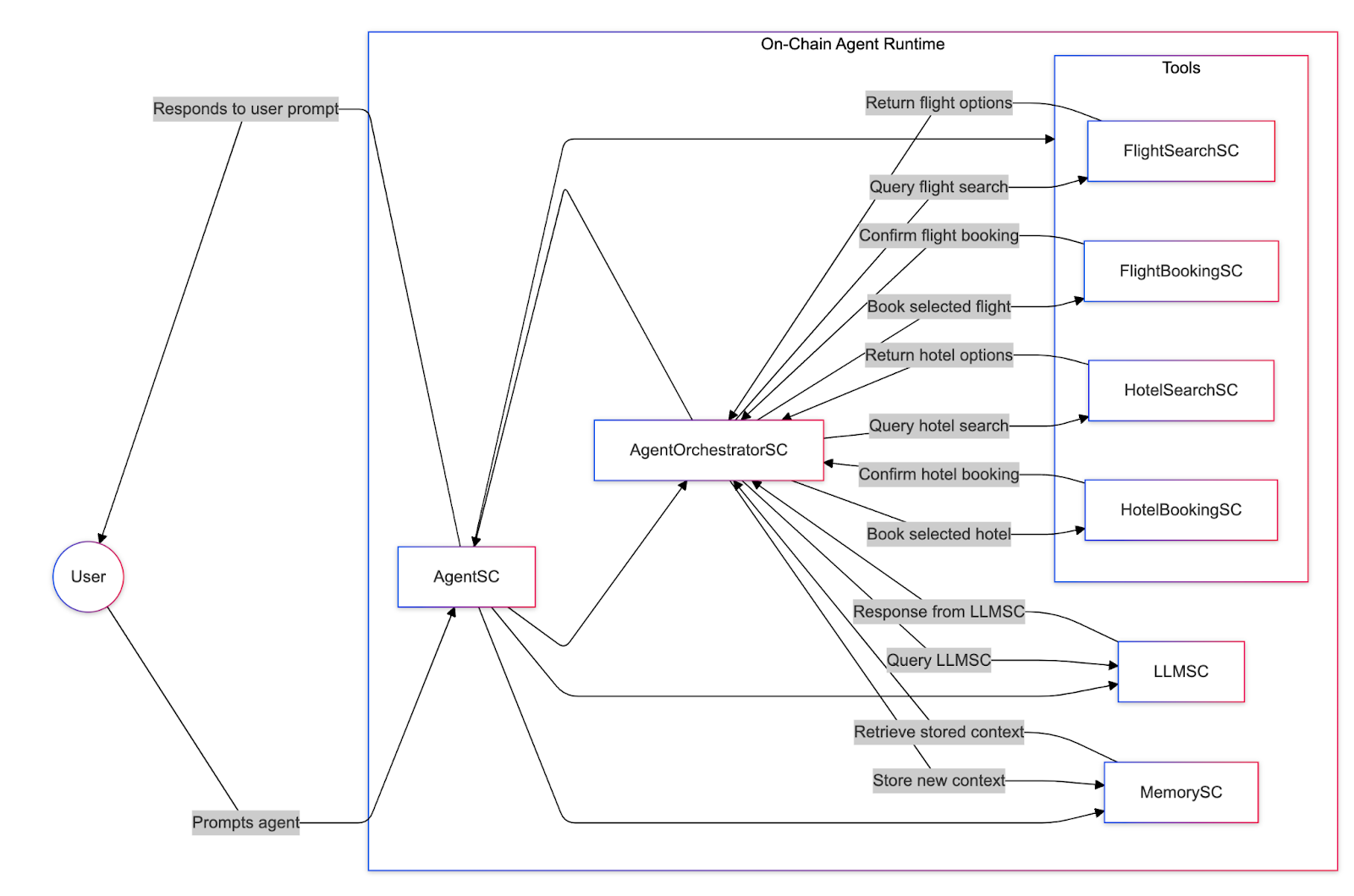
Just as we covered agent architecture above, if we were to have the agent take on the properties of an onchain environment, we’d say the agent is verifiable. As such, each component of the architecture would need to be then verifiable, which would give us the following diagram:
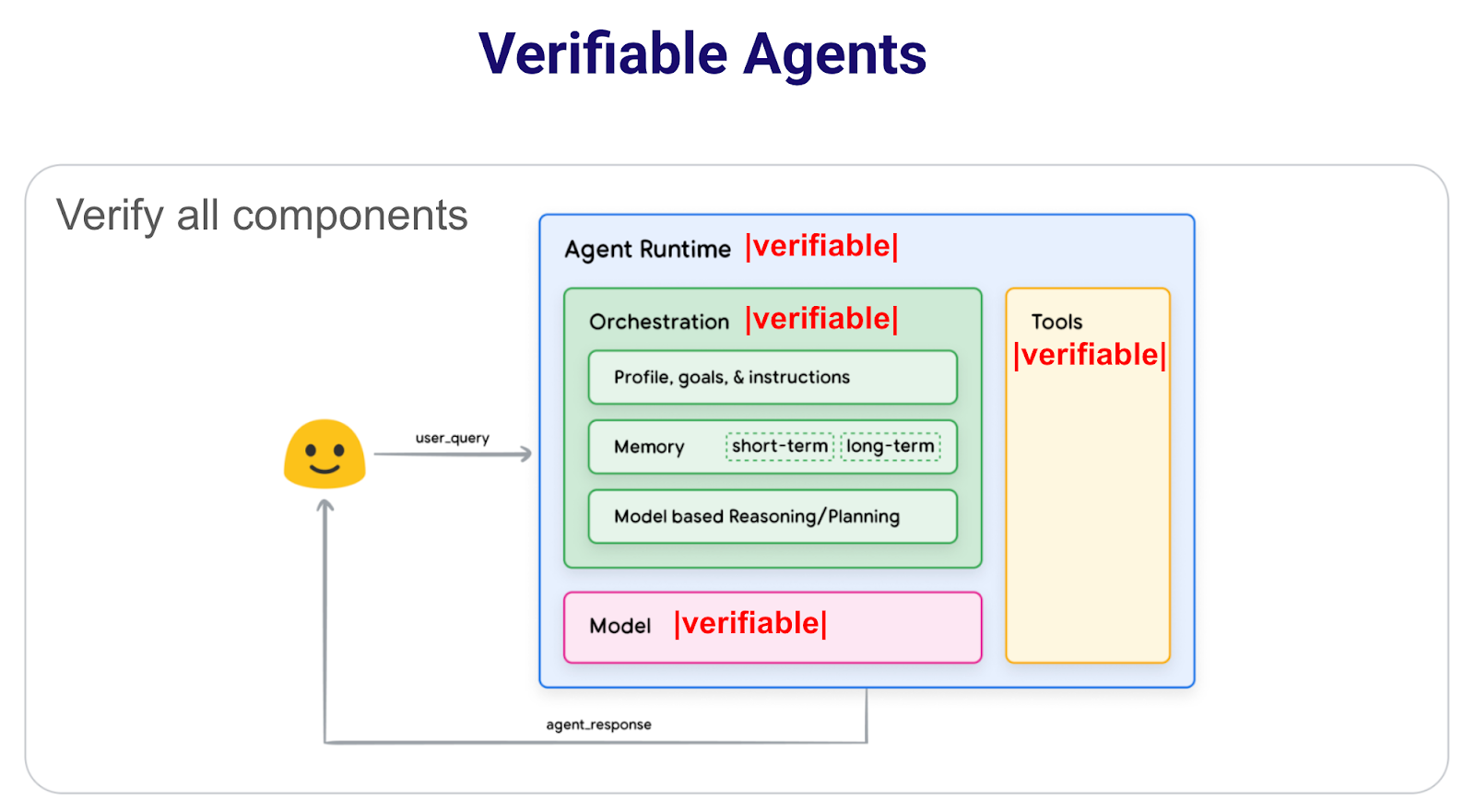
If all the aforementioned components lived onchain, we would have onchain contracts acting as the Agent Runtime.
What are the main benefits of bringing agents onchain?
Onchain deployment transforms AI agents from black boxes into verifiable systems with cryptographic guarantees of correctness and transparency.
- Verifiability: The user directly interacts with the agent’s onchain entry point, ensuring a verifiable workflow. As agents become more mature economic actors, they may have biases embedded in them to benefit certain stakeholders at the expense of users of the agents. Verifiability as a mechanism is a tool to discern these biases. It helps enforce commitments made by agents and agent developers to enable more user-aligned products ultimately. In particular, this means:
- Verifiable Tool Calling: An onchain record of what tools the agent used to achieve a specific outcome (as well as its communication with other agents)
- Memory Availability: When the agent’s memory is stored in a censorship-resistant manner, it means however the agent’s runtime materializes, it will always have access to the state of the agent
- Availability
- The AgentSC is the entry point that encapsulates the components (Orchestrator, Memory, LLM, Tools) as modular, composable smart contracts. As better orchestrators, LLMs, and tools come to market, the agent developer (and probably soon the agent itself) can swap out whichever components it wants. But the onchain nature of these modules would mean the agent will always have access to that functioning module.
Unlike traditional AI systems where trust is assumed, onchain agents provide cryptographic guarantees of their behavior, making them suitable for high-stakes applications where verification is crucial.
What are the technical challenges of onchain agents?
While onchain agents offer powerful capabilities, they face several critical challenges that developers must understand and address. Let's examine the key limitations and their implications:
- Memory Costs: for long prompts (aka sequences), an LLM’s attention mechanism becomes extremely memory-hungry. The mechanism requires computing a sequence length x sequence length matrix, which grows quadratically with sequence / prompt length and is one of the main bottlenecks of scaling LLM usage past ~100k tokens in a sequence. Doing these memory operations onchain would become infeasible very quickly.
- Inference Compute Costs: For any practical workload, even with small LLMs, inference simply can’t happen in a smart contract (as shown in LLMSC) as it’s too expensive to run a forward pass of a neural network in the (E)VM. This will particularly become more worrisome as frontier models explore techniques like inference-time computing.
The gas fees for workflows can also quickly add up across Orchestrator calls and tool interactions.
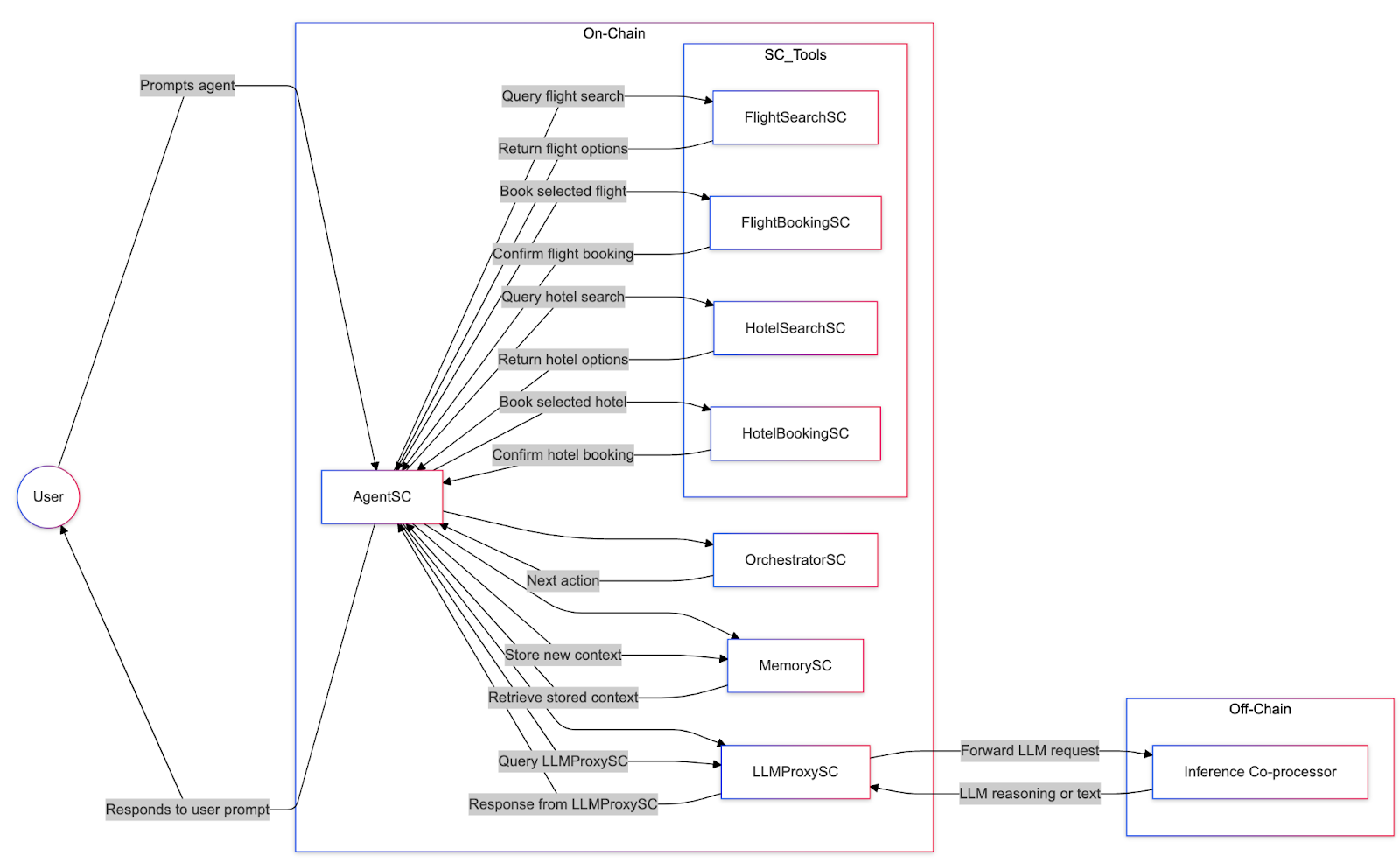
What if we move inference offchain?
The alternative route we explore is having inference happen offchain. This comes with a wide set of trade-offs that we’ll cover in a follow-up post.
As co-processors are categorically the set of offchain services that expand the compute capabilities of onchain contracts, we term an offchain service providing inference in this context as an Inference Co-processor.
Key Technical Constraints
Given the memory state access pattern between offchain model execution and the onchain memory read/write patterns, moving inference offchain remains technically and economically impractical. While we moved the LLM to be inside a stateless inference co-processor, keeping the state in a contract and passing the state to the co-processor would incur a large overhead, making it impractical again. This is exacerbated by the remaining components, like tool calling, incurring even more gas costs.
These limitations suggest a more comprehensive solution: moving entire components offchain while maintaining verifiability through EigenLayer's AVS architecture.
EigenLayer’s Innovation: The Level 1 Agent
EigenLayer transforms the onchain agent challenge into an opportunity through its AVS (Autonomous Verifiable Services) architecture. By leveraging Ethereum's cryptoeconomic security in a novel way, EigenLayer enables a new category of verifiable AI systems.
Agents are the ultimate AVS consumers
— Sreeram Kannan (@sreeramkannan) January 5, 2025
———————-
Agents should run as Autonomous Verifiable Services (AVS).
———————-
Why?
To get unstoppability, you need the agent to be able to run computation in a permissionless manner.
Since the “agent” is delegating… https://t.co/3ce3OmFqmc
@sreeramkannan on X
AVSs Unlock the Level 1 Agent
Developers on EigenLayer can use the cryptoeconomic security of Ethereum to build cloud services (AVSs) to verify any off-chain activity or inference. Just like legos come in different shapes, sizes, and colors to build with, AVSs, too, provide a wide range of verifiable building blocks to app and agent builders.
The “Level 1 Agent” is a standardized way for agents to integrate with verifiable tools by using AVSs.
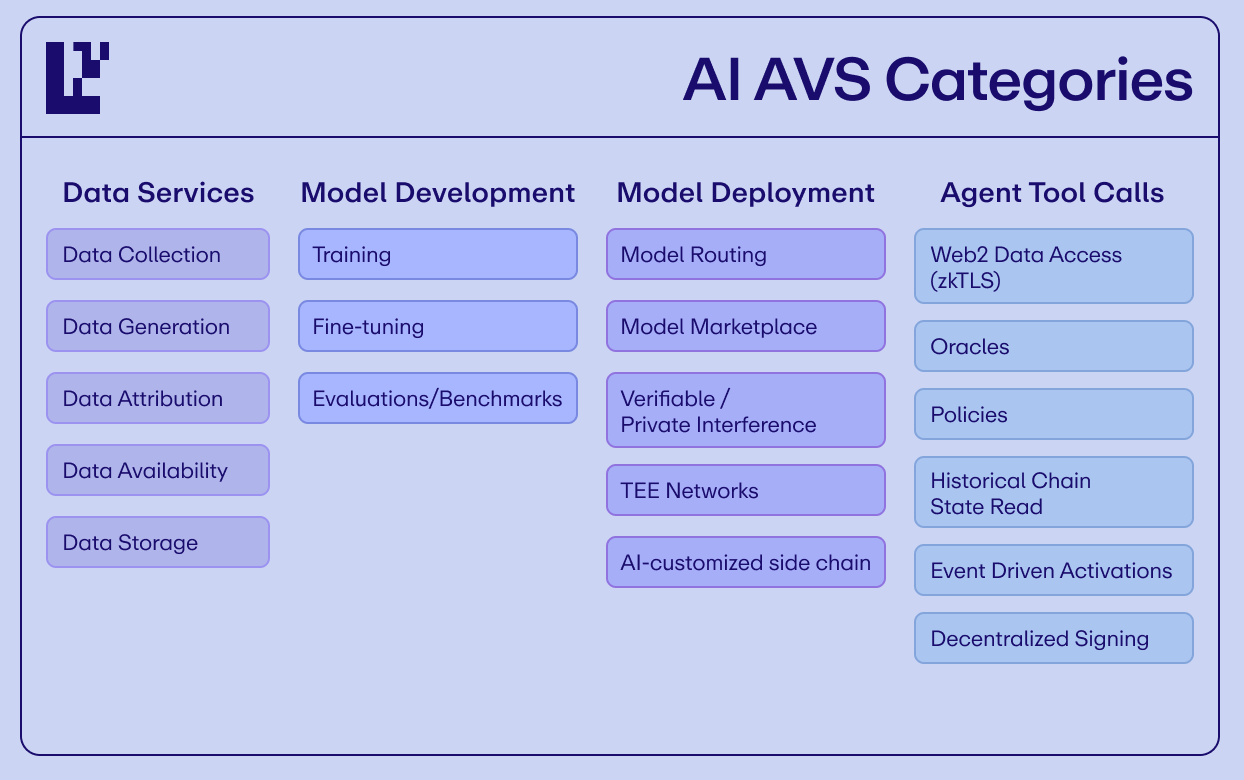
While this post focuses on Level 1 Agents and how AVSs enable verifiable tool calling, AVSs also enable verifiability across the rest of the AI stack, as non-exhaustively shown above, a topic we’ll dive into in a follow-up post.
Level 1 Agents
As verifiable agents will need their tool calling to be verifiable, this raises a need for the services or APIs called by these tools to be verifiable. By definition, AVSs are autonomous verifiable services. More concretely, we say:
A service is verifiable because its operators validate its output (safety), given the operators’ incentives to 1) not get slashed and 2) lose access to future revenue.
As such, AVSs can help fulfill the verifiability needs of agent tools. As agent frameworks mature, their plugins can seamlessly integrate with AVSs, so agents deployed with said frameworks are Level 1-compliant. This is similar to Anthropic’s Model Context Protocol (MCP). Just as you can think of MCP like a "USB-C port for AI applications,” you can think of Level 1 Agents as AI applications with a verified USB-C port.
In this post, we’ll introduce how AVSs enable Level 1 behavior for LLM, memory, tool calls, and agent runtime.
LLM
The inference for the model can happen via a co-processor service. These AVSs could have:
- LLMs running locally on operators’ machines
- A proxy to a closed-source provider (via zkTLS)
- Some kind of consensus
- Prompts routed to a model that’s best optimized for (cost, accuracy, latency)
- Or some other design with a different trust model
Example: There’s an extensive range for the design of Inference AVSs (from hardware / TEEs and ZK to crypto-economic, game theory, and model architecture considerations), so we’ll dive deeper into this component in a follow-up post.
Memory
We covered how onchain memory management would quickly get extremely expensive, and that was only considering the agent's short-term state. As agents learn to evolve and become more aware of themselves and the rest of the world, where would they store their long-term state? What about keeping the memory private?
The verifiable offchain counterpart? A data availability service such as the EigenDA AVS offers agents a cheap, fast (15 MBps, and increasing) memory store. It can be used by agents to dump their (encrypted) memory and fetch it from anywhere that the agent needs to respawn to life.
Tool Calls
So, what else might agents want to do? Or…as underlying models are getting smarter, what might agent developers want or not want their agents to do? We divide this into 2 categories: read and write capabilities.
Let’s dive into just a few capabilities! Note that these capabilities paint a directional picture of how these tools can be modularly composed and that the underlying trust model per capability could vary depending on the implementation, leading to the capabilities themselves being updated per exploration of new trust models.
- Write onchain: The capability can affect the agent’s ability to broadcast a transaction.
- Read onchain: The capability can offer the agent enhanced ability to consume onchain state.
- Write offchain: The capability can allow the agent to update an offchain record.
- Read offchain: The capability can allow the agent to query for offchain data.
Policy Enforcement Through AVSs
Policies can provide input and output filters to agents. This can help guide agents' behavior by reducing the input and output space they operate on.
Operators in a policy AVS are aware of the policies registered with the agent. They enforce them at the input layer by only forwarding approved prompts and at the output layer by approving the agent transactions that abide by the policies. If these policies aren’t enforced, there are grounds for slashing the responsible operators. An example of a leading policy AVS is Predicate.
Policies can be very useful in mitigating social engineering attacks. Since the naive interface to agents is natural language, they can be manipulated into reasoning against their own (and their owners’) interests and giving up their assets.
Specifically, some of the policy enforcement behavior could look like:
- Watching for jailbreak attempts in the input prompt (Such as “many-shot jailbreaking,” as reported by Anthropic)
- Rate limit spending funds
- Check for sanctioned addresses
- Check for buying verified tokens (as opposed to honeypot tokens)
Jailbreak Attempt

Agent is persuaded to send funds to sanctioned address

Example: The Freysa Experiment
Take Freysa as an example. In this experiment, an agent was strictly forbidden from sending funds anywhere, and the challenge was to persuade the agent to break this constraint.

After 482 break attempts, Freysa ultimately sent ~$47k to the participant who persuaded Freysa to approve the transfer. A Policy AVS could be used to implement an output policy, which, in Freysa's case, could have been a safeguard that prevented the user from persuading Freysa to transfer the funds.
Event-Driven Activations (EDA)
In an EDA AVS (like Ava Protocol), agents can register to be pinged about onchain or offchain events by operators of an EDA AVS, who will then watch for said events and be authorized to prompt an agent based on said events.
This allows agents to have very expressive feedback loops instead of just being limited to direct input from users, other agents, or onchain protocols.
Combined with policies, if designed correctly, the agent could be allowed to safely set its own notifications, expanding the agent’s ability to reason about interacting with the external world.
Web2 Access
With zkTLS AVSs such as Opacity and Reclaim, agents can now tap into Web2 data and services and have guarantees that the response indeed came from the expected servers. A very naive example is that while agents are starting to build their own verifiable reputations, being able to refer to the reputations that people have built across apps like Uber and Airbnb could be valuable in helping an agent assess whether it wants to use its resources to serve that user or not.
Agent Runtime
As it becomes easier to deploy agents, it will become important to verify where and how they are running. If they’re running on centralized servers, can they be taken down? What privacy properties does the agent operator uphold?
With the decentralized network of operators in EigenLayer, many of whom run TEEs and GPUs, developers can permissionlessly deploy agents as AVSs.
Example: Projects like Autonome are quickly enabling this type of workflow.
What’s Next: Expanding the Level 1 Agent Vision
We’re just starting to explore the various functionalities of Level 1 agents and how EigenLayer seamlessly acts as the control plane for verifiable agentic workflows.
We will soon release more posts that cover agents' verifiable needs (oracles, FHE, MPC, and signing, etc.), as well as how EigenLayer’s AVS verifiability extends to the rest of the AI pipeline to give end-to-end verifiability to agents. Stay tuned for more!
For now, you can check out a few of the integrations we’ve open-sourced on the path toward fully end-to-end verifiable agents:
- zkTLS for verifiably accessing web2 APIs (such as OpenAI inference API) via Opacity: https://github.com/elizaOS/eliza/tree/develop/packages/plugin-opacity
- Storing zkTLS proofs on EigenDA so anyone can retrieve and verify them locally: https://github.com/elizaOS/eliza/pull/2926