EigenDA V2: Core Architecture
100 MB/s. 75x faster than the next best competitor. Cloud-scale data availability with full programmability.
In a world of single-digit MB data availability solutions, EigenDA dares to dream bigger. We launched V2 on mainnet in July at 100 MB/s, with ambitions to scale to gigabytes of data throughput.
This article is the first in a technical series on how we got here. Today, we'll explore the core architecture that makes this level of scale possible. In future posts, we'll dive into GPU-accelerated erasure coding and LittDB, our custom database that outperforms traditional databases by 1000x.
The 100 MB/s Reality Check
Before diving into the mechanics of EigenDA V2, let’s start with the numbers: the clearest proof of what the system can do.
EigenDA V2 comfortably sustains 100 MB/s of data writes — 12.8x Visa's throughput capacity. Users see an average end-to-end latency of just 5 seconds, with P99 at 10 seconds. This represents a 60x decrease in latency, moving EigenDA from "usable" to "real-time."
But data availability isn’t only about writes; it’s about serving the entire network of readers. In practice, far more nodes will read than write. EigenDA V2 enforces a 20x read-to-write ratio, pushing 2,000 MB/s of data reads across the network. This is a new industry standard: not just scaling writes, but scaling reads to match the reality of rollup demand.
We proved this under near-mainnet conditions: we split stake across 14 independently run validators on Holesky, spread across North America, Europe, and Asia. Over 60+ continuous hours of load testing, EigenDA not only sustained its headline throughput but repeatedly exceeded it.
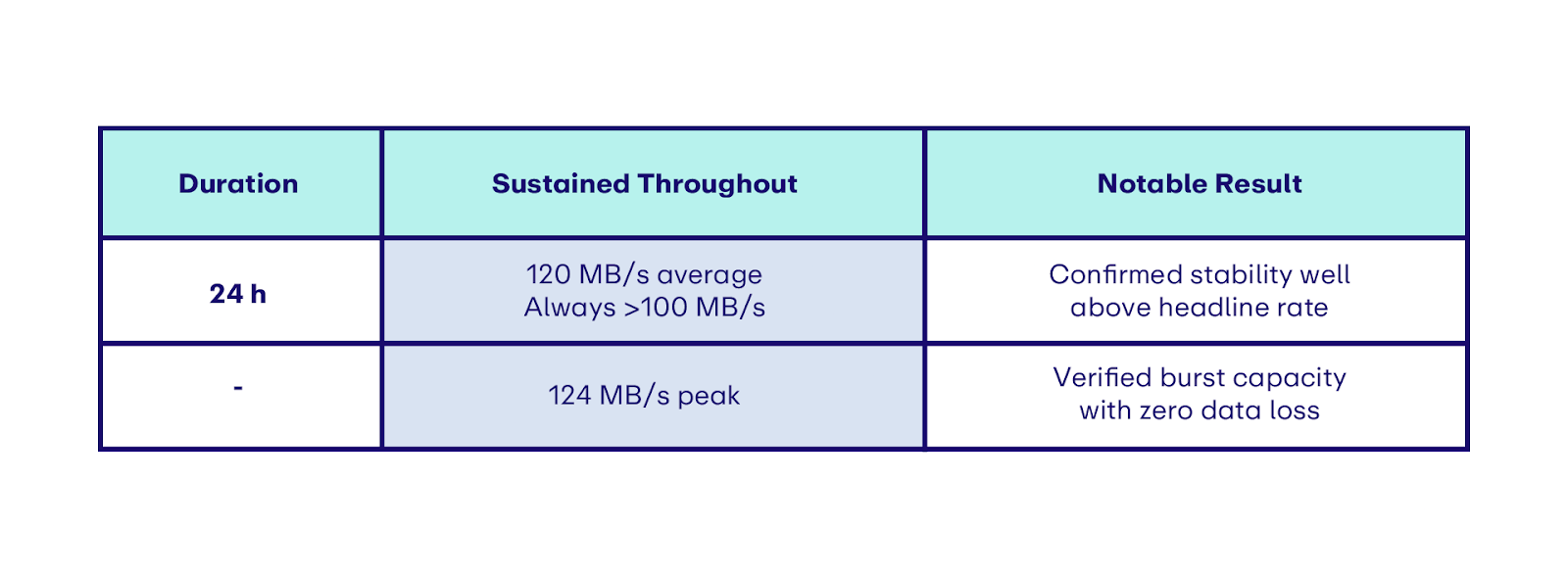
The contrast to just a year ago is stark: throughput is up ~6.7×, while end-to-end latency fell from ~10 minutes to seconds. Previously, all chains fit on EigenDA; now EigenDA operates at payment network scale – a system engineered for real workloads, at real scale, in real time.
Breaking Tradeoffs: The Case for EigenDA
Just as rollups scale Ethereum execution, EigenDA scales Ethereum data availability. The goal is simple but ambitious: maintain a permissionless operator set, minimize data overhead, and maximize data throughput, all at once.
Rollups must publish their data so anyone can verify execution and reconstruct state if needed. Today’s rollups publish data in three ways:
- Ethereum (blobs/calldata): Post directly to L1.
- Multisig / Data Availability Committee (DAC): A multisig of permissioned validators that attests to data.
- Decentralized DA network: A validator set secured by cryptoeconomic stakes, purpose-built for DA.
Posting data to Ethereum ensures availability, yet it limits rollup throughput. Even with full danksharding, several years away, all rollups share a combined 0.68 MB/s, enough for 1000 swaps per second. On the other hand, DACs are fast and cheap but concentrate trust in a multisig.
EigenDA breaks these tradeoffs. EigenDA maintains a permissionless, stake-chosen validator set while keeping per-validator storage requirements low. Rather than force every node to store every byte, EigenDA targets a roughly constant replication factor across the network (about 8× today, configurable) using erasure coding.
The result is a horizontally scalable system: operators store only their assigned fragments, not whole blobs, so each new node adds capacity. Overall, EigenDA provides rollups with sound data availability guarantees at high throughput.
How EigenDA Achieves Cloud Scale
EigenDA's high-level goal is deceptively simple: store a client's data and make it retrievable for a fixed two-week window. But achieving this at scale requires careful coordination between multiple actors, planes, and flows.
Protocol Actors
There are 3 main actors involved in EigenDA.
- Client (Rollup): The client, often a rollup, sends blobs to EigenDA. They typically interact with the EigenDA network through the EigenDA sidecar.
- Disperser: The disperser receives blobs from clients, encodes these blobs into chunks, and disperses the chunks to the EigenDA validator set.
- Validator: Validators pull chunks from dispersers. They receive, verify, and sign a header attesting to the chunks, store chunks for two weeks, and serve data to others as requested.
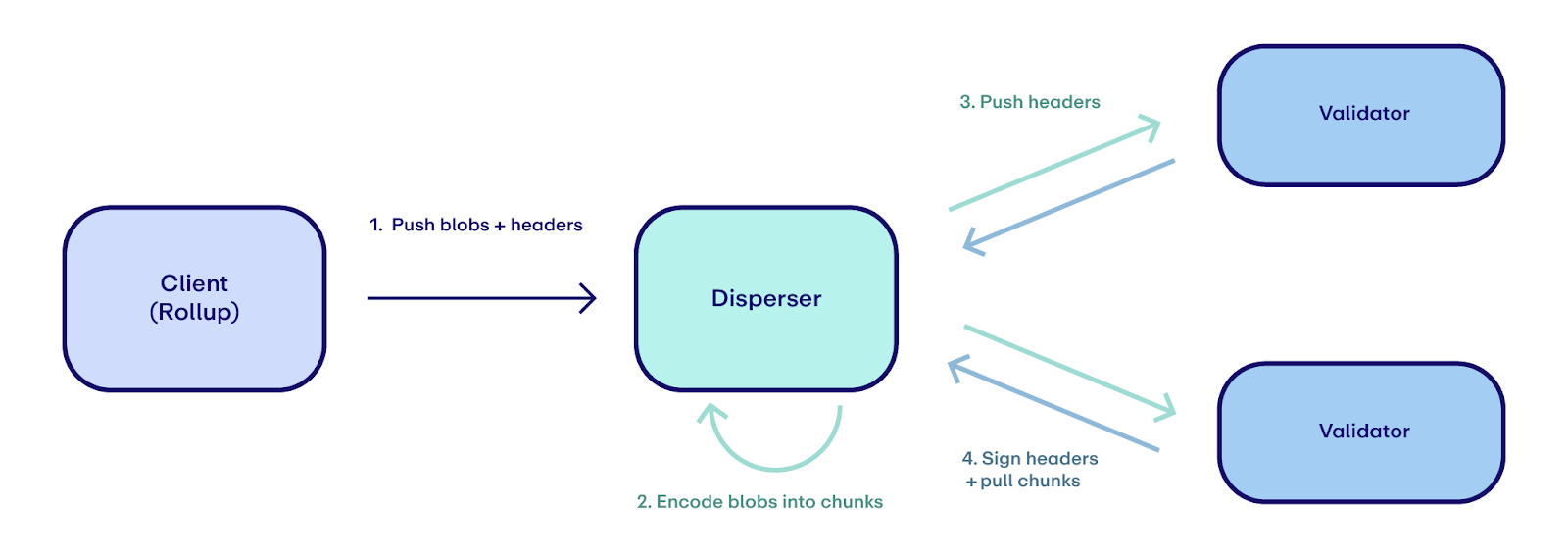
Control and Data Planes
EigenDA V2's breakthrough insight is treating coordination and bandwidth as separate pipelines. Each protocol actor operates on two planes: a control plane for lightweight metadata coordination, and a data plane optimized for high throughput. This separation is what enables EigenDA V2 to operate at high scale.
Notably, the disperser itself is a distributed system with multiple subsystems specializing in either control or data. The API server, blob store, encoders, and relays handle the data plane's heavy lifting. The metadata store and controller orchestrate the control plane's coordination logic.
The Blob Lifecycle
Here we illustrate how the different components of the systems work seamlessly together to offer 100MB/s in throughput.
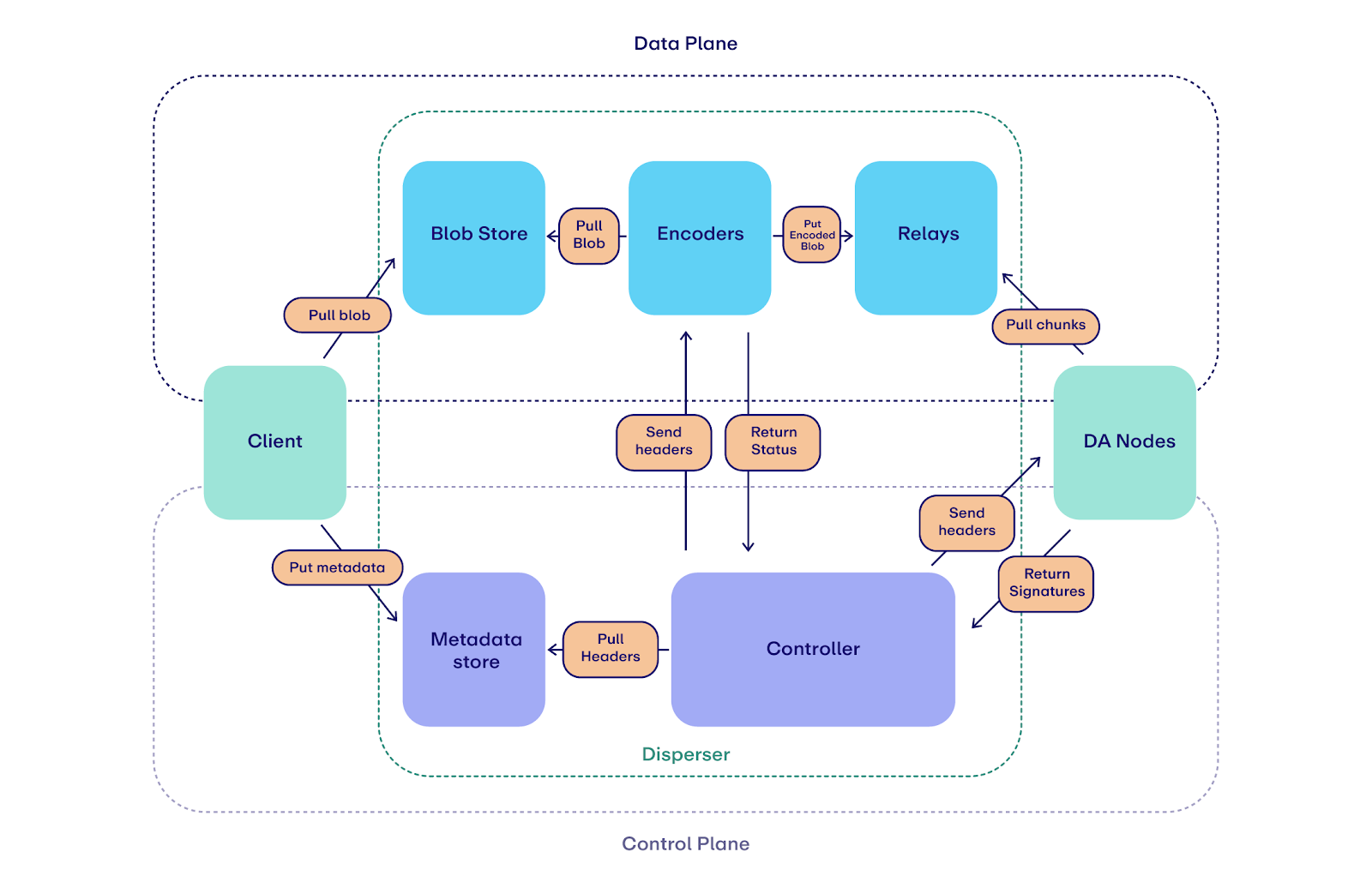
- Client submits the blob to a disperser. The client hands off a blob and the disperser accepts the job.
- Disperser stores the raw bytes and records the header.
- Data plane: The blob lands in the blob store, holding raw blobs immediately to prevent data loss if anything crashes.
- Control plane: The header lands in the metadata store, providing durability and a single source of truth for recovery.
- Disperser encodes the blob into chunks. The encoder pulls the raw blob and applies Reed Solomon erasure coding—a technique that adds redundancy so the original data can be recovered even if most pieces go missing. Each blob expands into 8,192 chunks (8x redundancy), but here's the key: any 1,024 of those chunks are sufficient to perfectly reconstruct the original blob. In theory, this means the system can tolerate up to 87.5% of nodes being offline while still guaranteeing data availability. The encoder also generates a KZG commitment that cryptographically proves the encoding was performed correctly, preventing malicious encodings.
- Disperser stages chunks to relays across regions. The encoder uploads chunks to geodistributed relays, essentially serving layers positioned close to validators. This keeps later reads local and fast.
- Disperser sends headers to validators. Once encoded, the controller broadcasts just the blob header to validators. No bulk data moves on this path, as this lies on the control plane.
- Validators verify headers. Validators check that headers are well-formed and that blobs are paid for (avoiding wasted work). They identify which chunks to pull from nearby relays.
- Validators pull chunks and KZG openings from relays. After verifying metadata, each validator requests its chunks from a nearby relay. They validate these chunks and the KZG opening against the header before signing and returning the header to the controller. Chunks are stored for two weeks using LittDB, our custom performant database designed specifically for data availability.
- Disperser aggregates signatures and certifies the blob. The controller aggregates validator signatures into a DA certificate and returns it to the client. The blob is now confirmed, and anyone can retrieve it by header.
In short, the client hands off bytes, the disperser cuts and stages them, validators verify and sign, and the network holds the pieces for two weeks.
Two Planes, One System: How Separation Unlocked Scale
The control/data plane separation wasn't immediately obvious. EigenDA V1 shipped with the disperser treating blobs and headers indiscriminately, quickly hitting a throughput ceiling at 15 MB/s.
Fortunately, we built EigenDA as an AVS. Rather than being locked into a uniform architecture where every node plays the same role, we could experiment with more flexible designs. This unlocked 60 years of distributed systems wisdom that we could easily apply to our problem.
Taking inspiration from Kubernetes and Kafka, we split "what should run" (control plane) from "actually moving bytes" (data plane). Small, latency-sensitive decisions stay isolated from bulk workload execution. Each path is engineered for its specific job, and they run in parallel.
Control plane wins:
- Dispersers push only headers—kilobytes that are easy to rate-limit and cheap to authenticate
- Validators can accept headers from many independently run, permissionless dispersers without risking a flood of bulk data
Data plane wins:
- Validators pull chunks from nearby relays
- Bandwidth scales with relay capacity, not validator or disperser count
- Slow nodes don't stall others
The results spoke for themselves:
- Throughput increase: Previously, the disperser pushed data to all validators sequentially. Slow validators created backpressure, causing retries and limiting throughput to 15 MB/s. The pull model eliminates this bottleneck—validators fetch from relays in parallel, removing the dependency on the slowest connection.
- Path to permissionless dispersers. Previously, accepting data from unknown dispersers meant risking gigabytes of spam. Now validators only accept small headers (kilobytes), making it safe to open access. Validators can open up to many dispersers while keeping a small, predictable ingress surface.
The 10x Encoder: How Removing Features Added Performance
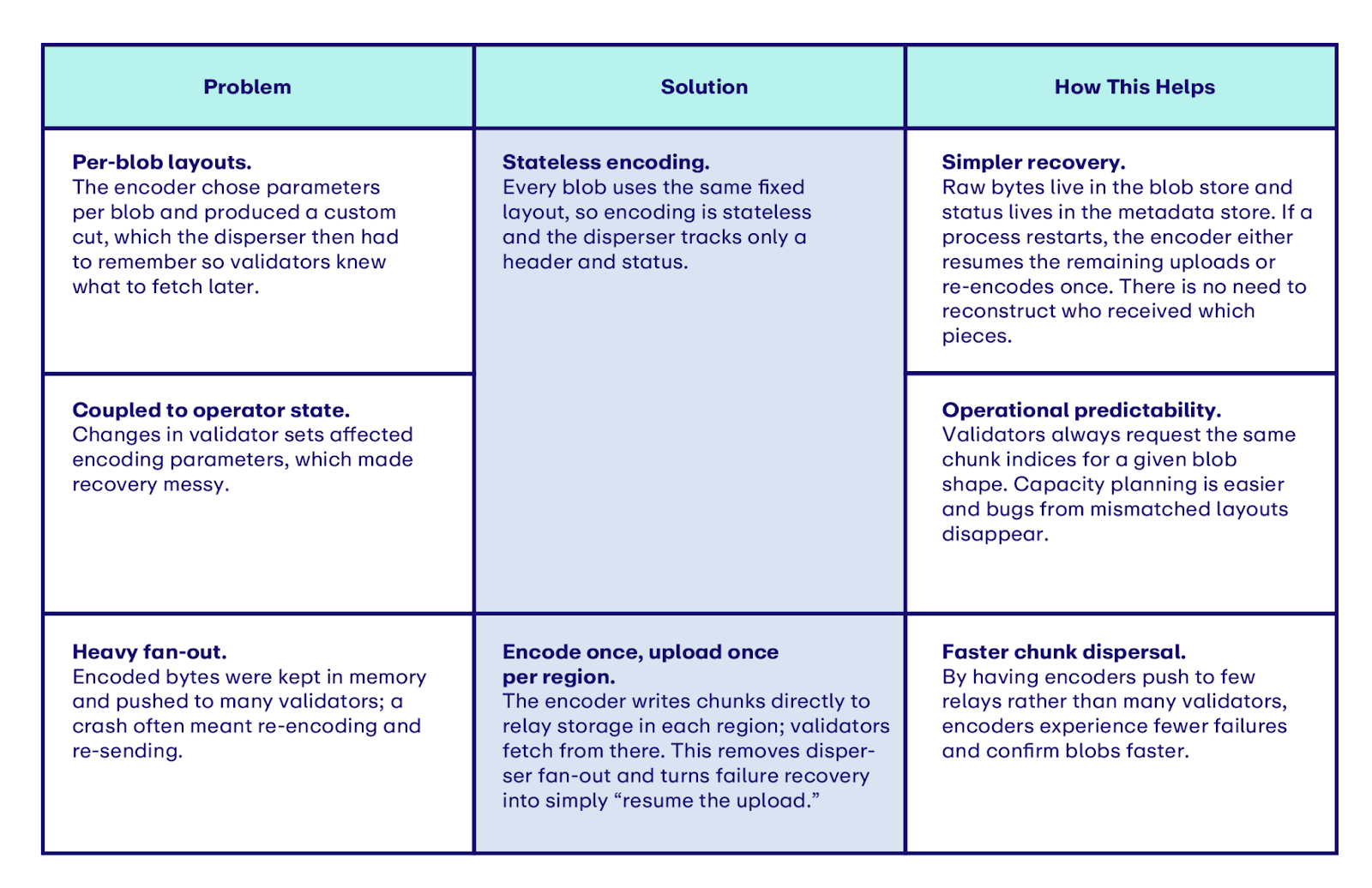
After splitting the control and data planes, the encoder became the new bottleneck. In V1, encoding depended on blob size, quorum choices, and the operator's live view of validators. Our solution? Radical simplification.
Specifically, we did two things:
- Stateless encoding. By making encoding a stateless function, encoding becomes a repeatable process for every blob. This enables simpler data recovery and minimizes spikes in end-to-end latency.
- Encode once, upload once per region. Rather than upload chunks to each validator, the encoder only needs to upload chunks to each relay. Assuming 1 relay per region, this drastically reduces the encoder’s load, reducing the frequency of crashing.
Confirmations at the Speed of Trust
A blob is confirmed when enough validators (55% of stake by default) have signed a certificate committing to that blob. From that moment, a rollup can safely act on the blob, as the network has attested that the data is retrievable.
Previously, the disperser batched certificates to L1 every ten minutes. Not only did this cost gas on every blob, but it also meant rollups waited ten minutes for finality. Safety at the cost of speed.
We borrowed a page from rollups themselves. Just as rollups execute transactions offchain and only escalate in the unhappy path, EigenDA V2 now returns signed certificates immediately without posting to L1. Rollups can accept these certificates optimistically or embed verification directly in their ZK proofs. L1 posting becomes a fallback for disputes, not a requirement for every blob.
The result: ten-minute batching became ten-second confirmations — a 60x reduction in latency. The happy path stays fast and cheap, with L1 security still available when needed.
Looking Forward: The Road to Gigabyte Scale
EigenDA V2 represents a fundamental reimagining of what data availability can be. By separating control from data, simplifying our encoding pipeline, and making confirmations optimistic-by-default, we've built a system that doesn't just incrementally improve on existing solutions—it operates in an entirely different performance class.
But we're just getting started. The architecture we've built isn't just about today's 100 MB/s—it's about tomorrow's gigabyte-scale requirements. Every design decision, from our horizontally scalable validator model to our geodistributed relay network, was made with an eye toward the massive scale that a truly global, verifiable internet will demand.
By the end of 2025, we're shipping:
- Permissionless Disperser: Opening the gates for anyone to post data to the EigenDA network.
- Slashing: Preventing misbehavior with economic penalties with EIGEN token forking.
- Further Throughput Scaling: Meeting the data needs of a verifiable internet, because 100 MB/s is just the beginning!
The future of blockchain isn't about choosing between security and scale. It's about building systems that deliver both. With EigenDA V2, that future is here.
If you’re interested in building these on our roadmap to cloud-scale data availability with full programmability, we’re always hiring. Check out our open roles, or reach out to our EigenDA General Manager Kydo.
If your rollup or verifiable app wants to unlock cloud-scale throughput, check out our docs or email us.
And as mentioned, this is just the first blog in a series of 3 technical posts explaining EigenDA V2. To learn about GPU-accelerated erasure coding and LittDB, subscribe to our newsletter and follow us on X (formerly Twitter).