EigenDA: LittDB for Cloud Scale DA
EigenDA is on a mission to revolutionize data availability for the next generation of blockchain applications. Our core goal is to provide massive scalability while maintaining the decentralized ethos that makes blockchain technology so powerful. Although it runs counter to conventional wisdom, we think cloud scale and verifiability do not need to be mutually exclusive concepts.
The Database Bottleneck: Why Traditional Solutions Failed Us
When we initially built the EigenDA data storage engine, we did what most developers do: we reached for a battle-tested open source solution. We began with LevelDB, a reliable key-value store developed by Google that has served countless applications well including Geth.
It's simple, too. Simple is good!
But as our system grew and our performance requirements became more demanding, LevelDB's limitations became painfully apparent.
We had two fundamental problems with LevelDB.
First and foremost were throughput limitations.
Its maximum write throughput is not near our desired performance of GB/s, and read/write latencies are often measured in minutes when the database is experiencing high load. On disks provisioned to handle 1GB/s write traffic, LevelDB struggled to sustain 0.5MB/s. LevelDB could achieve a much higher burst write speed than this. But burst write speed is significantly less important than long term staying power for EigenDA’s workload. It’s critical that our data storage engine be capable of running for years at a time at peak operational load.
Secondly, LevelDB behaves poorly when under stress.
LevelDB lacks a fundamental safety mechanism: back pressure. If you push data into a database faster than the database can properly ingest, a safe system that implements proper back pressure will push back and say “Woah, that’s too fast! Wait a little while while I clear my backlog.” LevelDB does not do this. As it falls further and further behind, it gets slower and slower, while simultaneously consuming more and more memory. In extreme cases, we even observed LevelDB consuming the entirety of the host machine’s memory, leading to OOM crashes. Not small machines either – we’re talking enterprise grade servers with more than 100GB memory.
The root cause for these performance problems was compaction. As LevelDB databases grow larger, they spend increasingly more time performing compactions - essentially reorganizing on-disk data to maintain performance and to reclaim storage space. What started as a small percentage of disk I/O gradually became the dominant activity. When we attempted to scale EigenDA throughput, eventually the vast majority of our disk bandwidth and system memory was consumed by compactions rather than serving our actual workload. This was simply unacceptable for EigenDA, at the scale we envision.
Our team tested a variety of alternative database solutions, including BadgerDB, PebbleDB, LotusDB, and others. BadgerDB showed promise and came the closest to meeting our needs, but ultimately it had similar weaknesses to LevelDB. Although faster than LevelDB, its speed left a lot to be desired. More alarmingly, its back pressure was even more flawed than LevelDB. BadgerDB’s garbage collection breaks down under high sustained write load and is unable to keep up. Under high enough workload, eventually BadgerDB will exhaust all disk resources and crash, even though the majority of the data on disk is data that is eligible for immediate deletion.
The fundamental issue became clear: our workload is dramatically different from what typical general-purpose databases are optimized for.
Now, we're aware that distributed databases exist that could certainly scale to our requirements.
Systems like Cassandra, ScyllaDB, or CockroachDB have proven they can handle massive scale. But we made an intentional choice not to go down that path. We want something that is operationally simple to run. While some node operators may be running in sophisticated cloud environments, we want to make our protocol just as viable to run on a computer in an enthusiast’s garage. Standard, commodity hardware is more than capable of handling EigenDA requirements on paper, only if we could take advantage of it.
LittDB: Purpose-Built for Performance

The solution became clear: we needed to build our own database, purpose-built for EigenDA's specific requirements. Enter LittDB - a highly specialized embedded key-value store that ruthlessly optimizes for high throughput & low latency and throws away features we don't need (e.g. mutability, transactions).
The key insight driving LittDB's design is that EigenDA needs only a tiny subset of the features
typically found in general-purpose databases. By intentionally excluding unnecessary features, we can far surpass the performance of existing databases for our exact requirements.
The Zero-Copy Revolution
The most important architectural decision in LittDB is that it's a zero-copy database. Once data is written to disk, it is never moved or copied until it's eventually deleted. This might sound simple, but it's revolutionary for performance.
The only way to achieve zero-copy efficiently is to make entries immutable after they're initially
written. Since general-purpose databases all want to support updates, they never end up being zero-copy. LittDB completely eliminates the concept of compaction - and this is a massive performance improvement. No more watching your disk I/O get consumed by background maintenance tasks. No more performance degradation as your database grows. Just pure, predictable performance.
How Traditional DBs Work
At a high level, databases like LevelDB and BadgerDB have two parts: data files and an index.
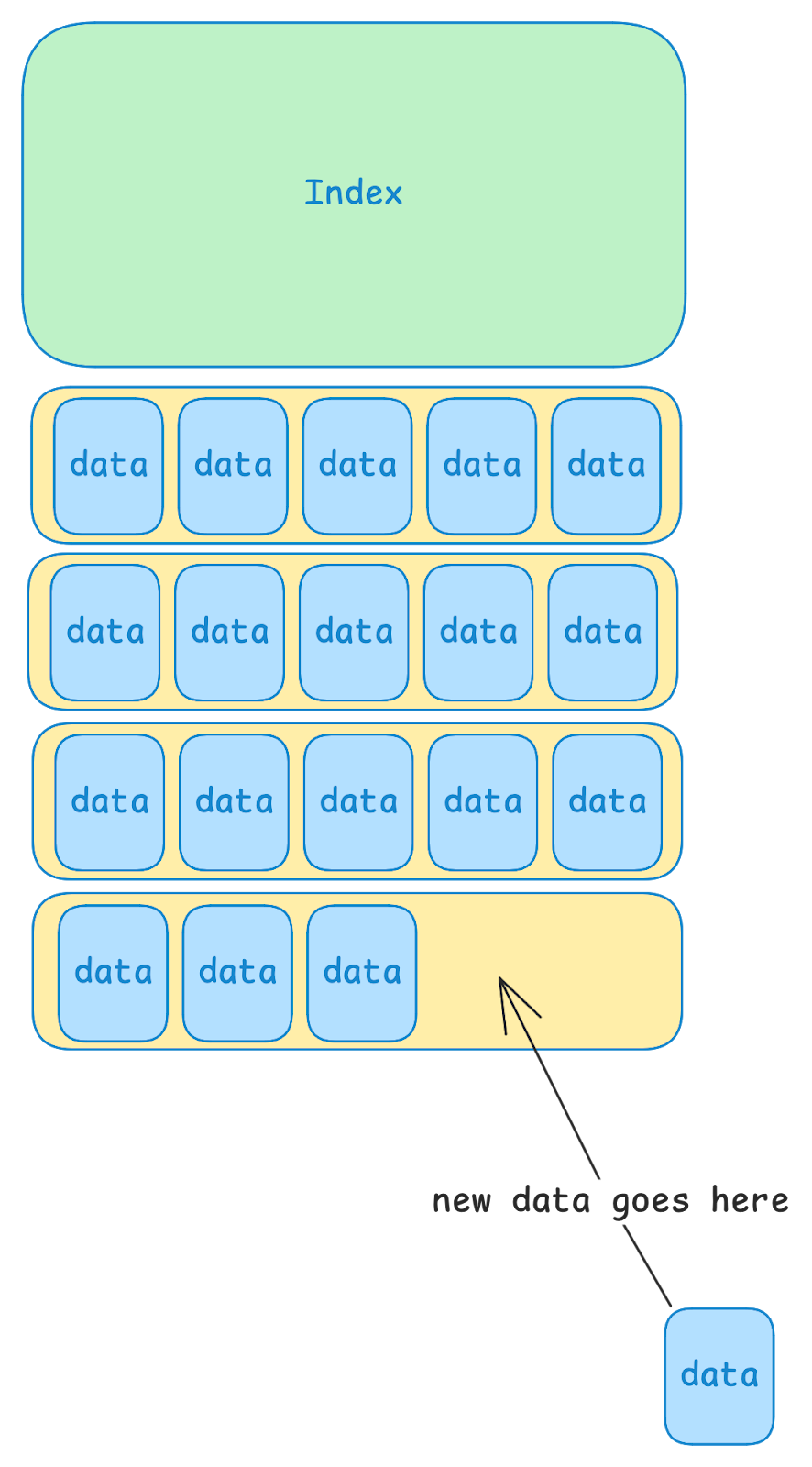
The database appends new values to the end of a data file. This results in large linear writes, which is much more performant than writing small values to random locations.
The index is a mapping from keys to the location where values can be found. There are a number of ways the index might be implemented, but a common strategy is to store data in a sorted tree.
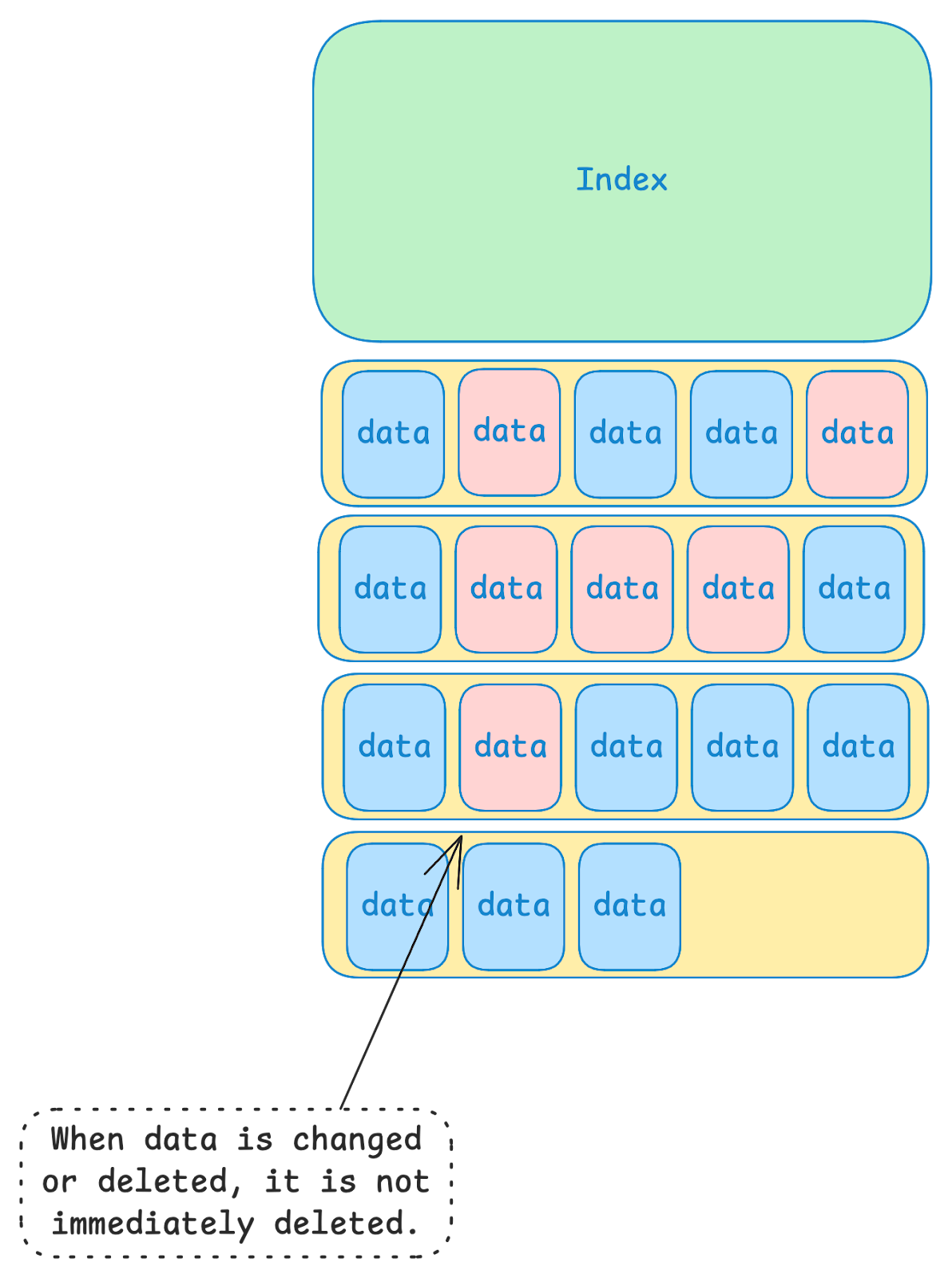
In the image above, the red boxes represent data that is “stale”. This could be because the value was modified, or because the entry was deleted, or because the entry expired due to a TTL (i.e. “Time To Live”). Since new data is always written to the end of the last data file, old values that are no longer relevant may persist for a while in old data files.
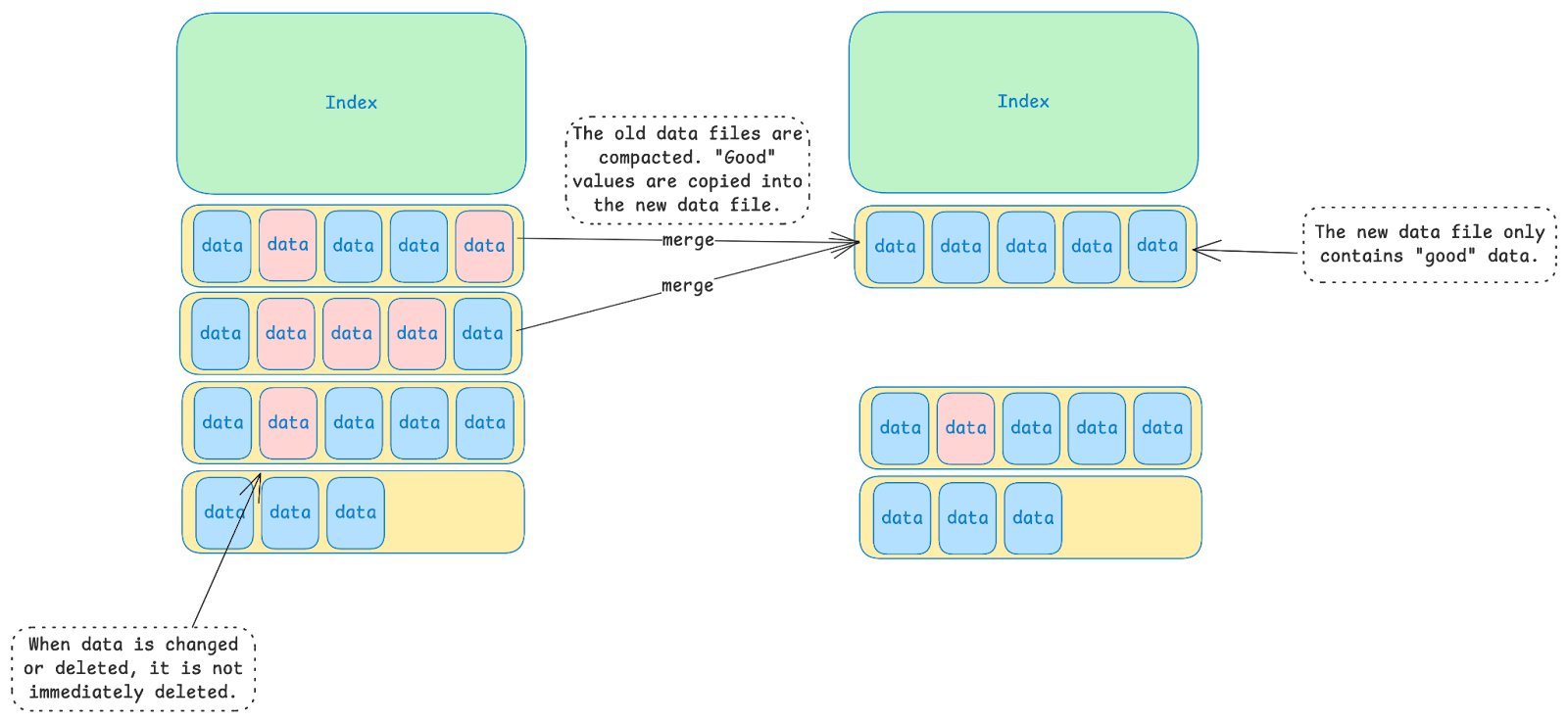
Periodically, a database like LevelDB or BadgerDB will perform an operation called “compaction”. The database merges together data files, throwing away expired values and keeping the values that are still needed.
Compaction is a very costly operation. Each time a value file is compacted, the file must be read into memory and then written back off to disk. If each value file is compacted once on average, then each X bytes of data written to the database results in 2X bytes of data actually being written. Even worse, assuming that each file only gets compacted once is a very optimistic assumption. In practice, each file will likely be compacted many times over its lifetime.
LittDB: A Database Without Compaction
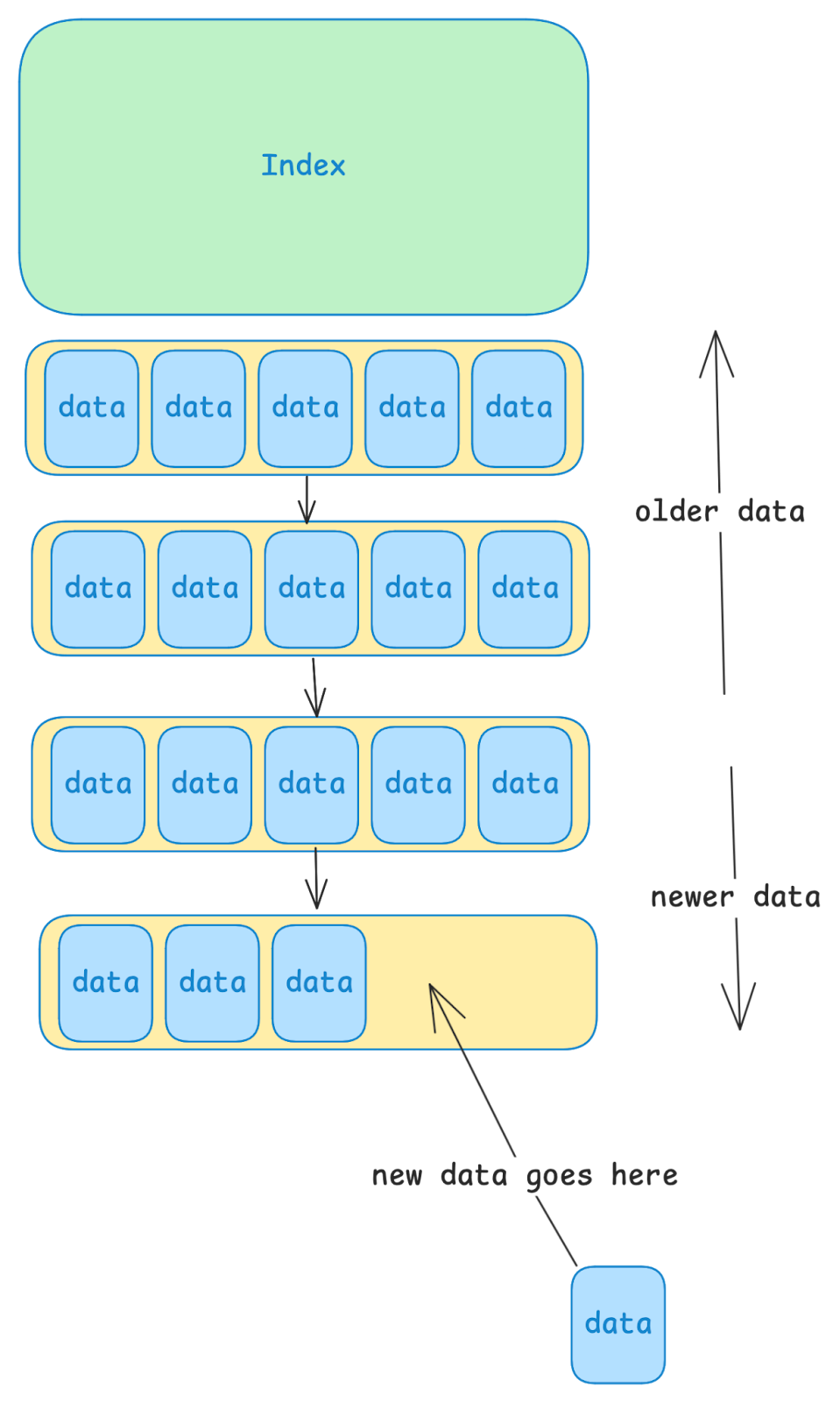
Similar to many traditional DBs, LittDB stores its data in large files, and maintains an index into those files. New data is always written to the end of the last data file. Importantly, LittDB maintains a strong ordering of its data files. Newer data always appears after older data. Data is never reordered.
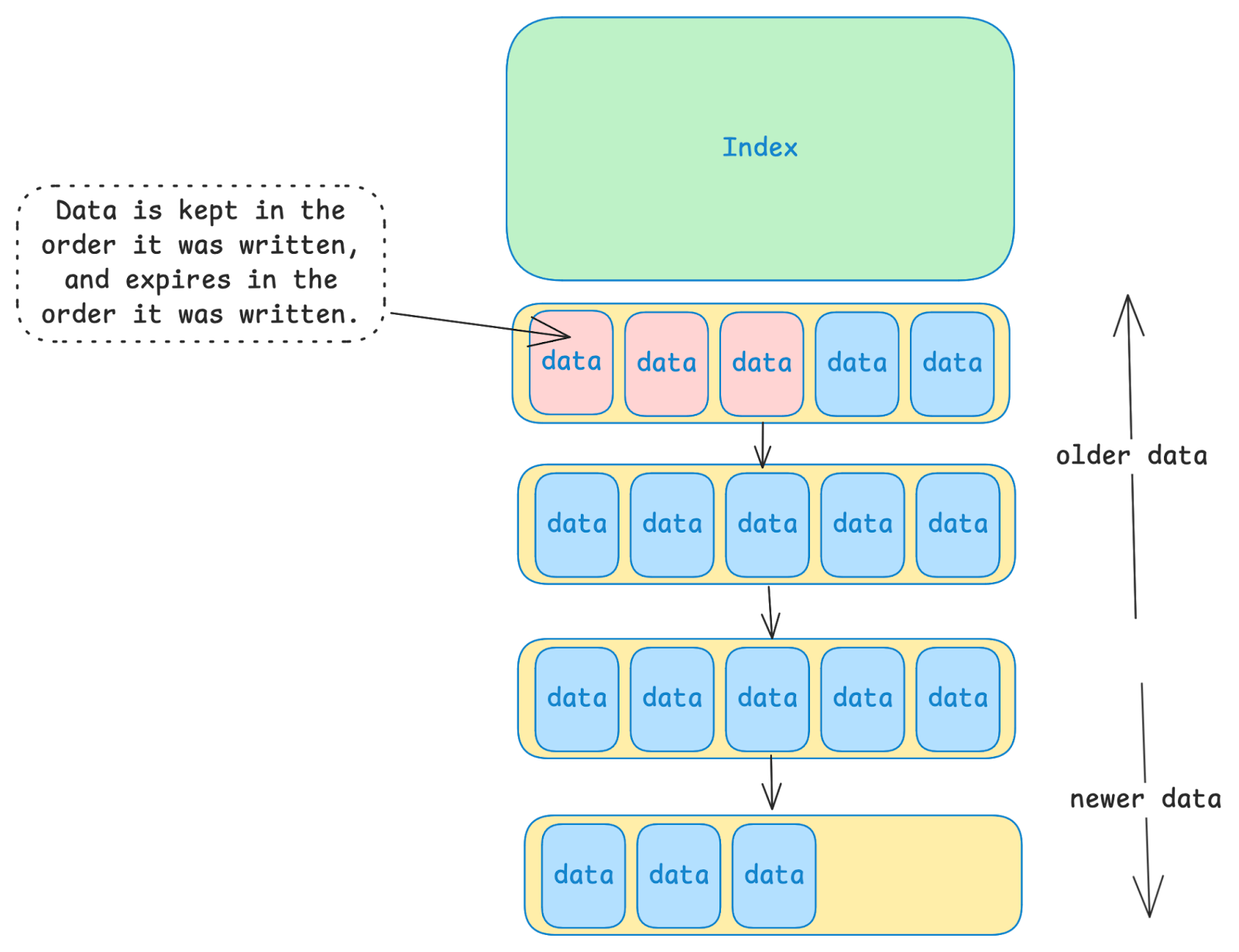
LittDB does not support data mutation. Once a value is written, it can never be changed. Data also cannot be deleted manually. The only way that data leaves the database is when its age exceeds the configured TTL (time to live).
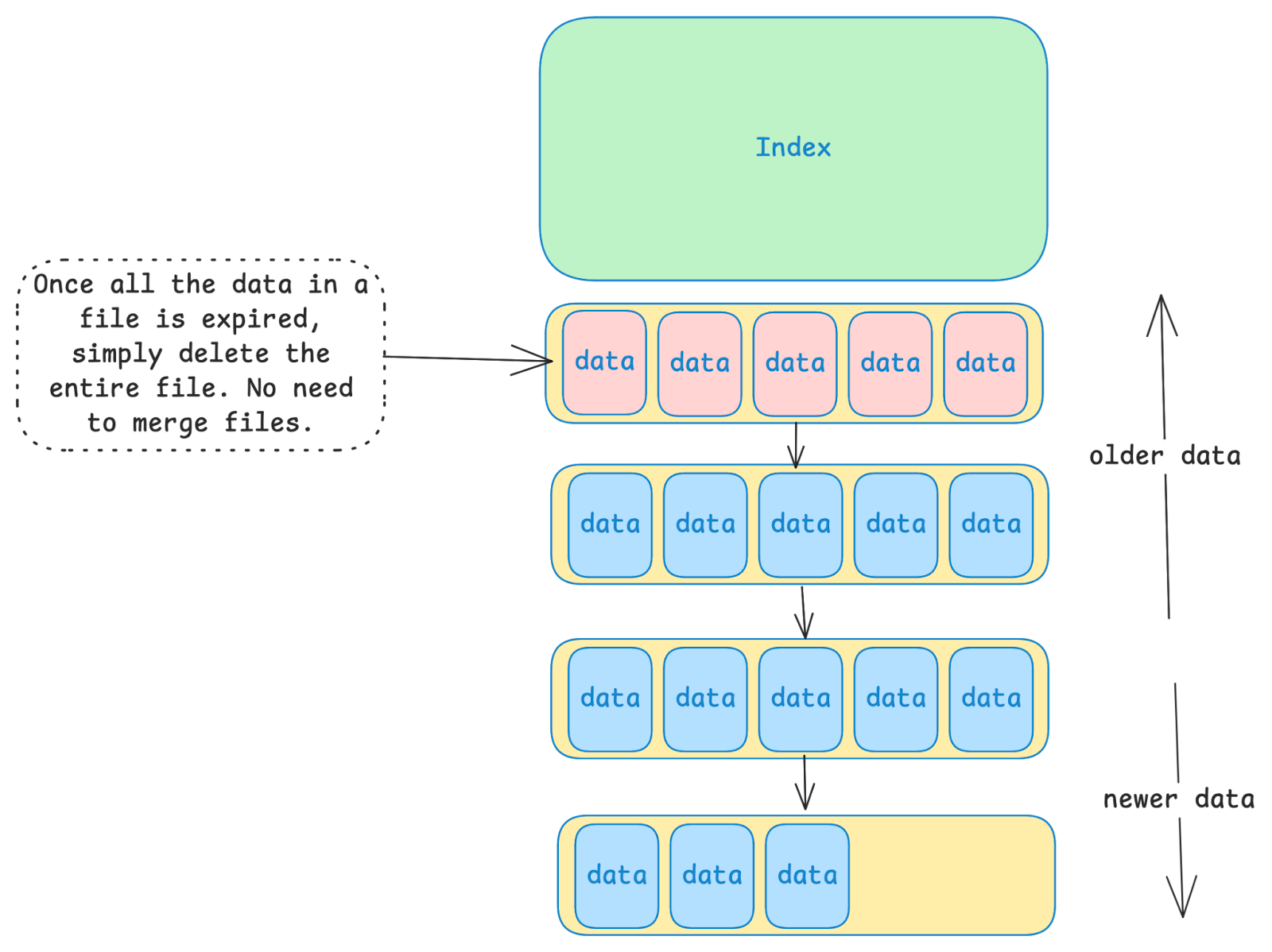
Because of this, the data in the DB becomes eligible for deletion in sequential order. This is very important. Unlike other DBs where many files contain a mix of “good” and “bad” data, only the oldest file will contain “bad” data, and all other files will contain 100% “good” data. To get rid of this “bad” data, LittDB can simply delete the file in its entirety, and doesn’t have to worry about extracting “good” data from it via compaction.
What LittDB Does (And Doesn't)
An advantage of building LittDB in-house is that we can create features that are perfectly tailored to solve the specific problems we face.
LittDB is intentionally focused on doing a few things extremely well.
Features:
- High-performance writes: Optimized for sustained high write throughput
- Low-latency reads: Fast data retrieval when you need it
- Write-once semantics: Data is immutable after writing
- TTL-based expiration: Automatic cleanup of old data
- Multi-table support: Separate namespaces for different data types
- Multi-drive support: Spread data across multiple physical volumes
- Incremental backups: Both local and remote backup capabilities
- Large data support: Keys and values up to 4GB in size
- Incremental snapshots: Efficient incremental snapshots that don't require downtime
- Thread safety: Safe concurrent access from multiple threads
Anti-Features (Things LittDB Intentionally Doesn’t Support):
- Mutations: Once written, data cannot be changed
- Manual deletion: Data only leaves via TTL expiration
- Transactions: Individual operations are atomic, but no cross-operation transactions
- Complex queries: Just "get me the value for this key"
- Replication: Designed for single-machine operation
- Data compression: Keep it simple, keep it fast.
More likely than not, the data in EigenDA isn't going to be very compressible.
- Encryption: Security should be handled at other layers
Would these things be nice to have? Yes? Maybe? But they would add a lot of complexity and would slow us down. When it comes to simplicity and performance, we will always choose to optimize for the core use case rather than trying to be everything to everyone.
LittDB vs LevelDB vs BadgerDB
Below are the results of benchmarking we ran when comparing LittDB against LevelDB and BadgerDB.
Methodology
These tests were run on an AWS m5.16xlarge. The disk was a 16TB gp3 volume, provisioned with 16000 iops and a throughput cap of 1000 MiB/s.
The code we used to perform these experiments is available here.
The experiment utilized the following configuration:
- 10MiB/s read traffic limit. Regardless of whether or not a DB is capable of reading faster, we capped read traffic at this level.
- Write traffic was not throttled. The benchmark engine attempted to write as much data as possible as quickly as possible.
- 4 hour TTL (time to live). DB is configured to automatically delete entries after they reach this age.
- 8 writer threads.
- 32 byte keys, 2MiB values.
- Batch size: 32. Each writer thread was required to flush all data out to disk at least once per 32 values written. Data flushed this way was required to be fully crash-durable when the flush method returned.
Note the workload we used may not be ideal for LevelDB and BadgerDB. This is, however, representative of what EigenDA needs to handle. Our interest wasn’t in setting up a “fair fight” for arbitrary access patterns, we were specifically interested in how this specific workload was handled.
Write Throughput
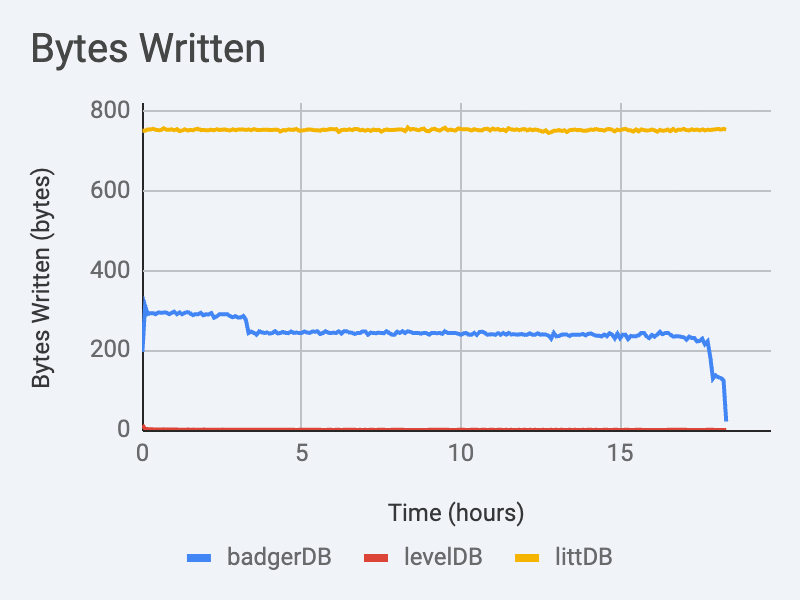

Write performance quickly degrades as LeveDB accumulates data. It is not a coincidence that performance stabilizes around the 4 hours mark. In this benchmark, the data TTL is set to 4 hours, and so after the 4 hour mark the size of the data contained by the database remains relatively constant.

There is a noticeable drop in performance near the 4 hour mark. The data TTL is 4 hours in this benchmark. BadgerDB compaction is very disruptive, and so it is not surprising to see performance degrade as soon as compaction has to start doing real work.
A major flaw with BadgerDB is that compaction cannot keep up with this workload. This benchmark crashed when it filled up the entirety of the 16TB disk. At 250MiB/s over a four hour data retention window, the expected disk utilization is 3.6TB. This means that at the moment BadgerDB crashed due to lack of disk space, 80% of the data on disk was eligible for immediate deletion, if only BadgerDB could delete it fast enough.

LittDB performance is highly stable at 1500x LevelDB’s write throughput, and 3x BadgerDB’s write throughput. LittDB’s performance shows no measurable difference regardless of the quantity of data stored on disk.
Read Throughput
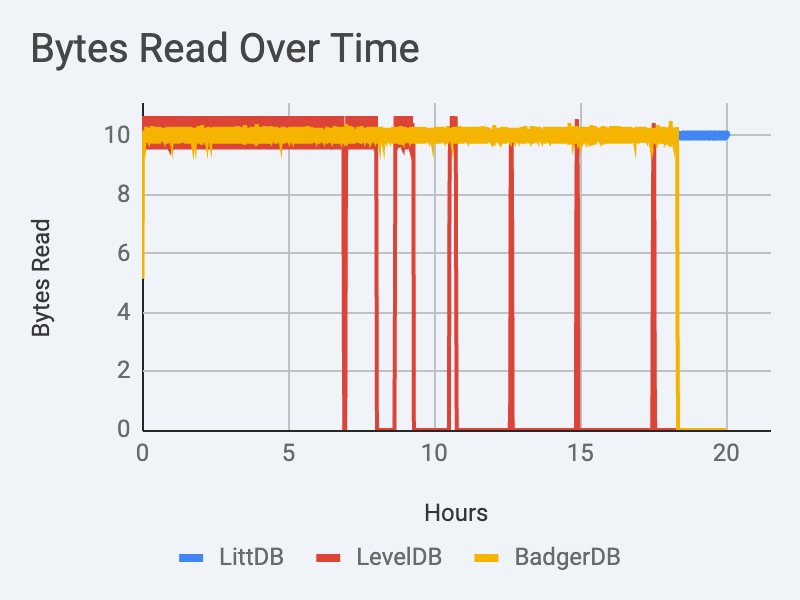
The benchmark visualized in this blog is primarily focused on comparing write throughput, but it did send a small amount of read traffic at the same time. Read traffic is intentionally throttled at 10mb/s.

Initially, LevelDB can keep up with the required 10MiB/s read traffic. Eventually it destabilizes, going hours at a time without being capable of serving any read traffic.

BadgerDB has no difficulty keeping up with the required 10MiB/s read traffic (at least, it doesn’t have trouble with this traffic up until the moment when it exhausted the disk and crashed).

LittDB is easily able to keep up with the required 10MiB/s read traffic.
Write Latency
The benchmark uses batched writes. Each batch contains 32 key-value pairs. Since each value is 2 megabytes in size, a single batch contains 64mb of data. The latencies shown below are the time required to write one of these batches.

LevelDB is very clearly overwhelmed and thrashing. As time progressive, it gets progressively slower and slower.

BadgerDB’s write latency is moderately low, up until the end of the benchmark when things rapidly destabilize. This is due to BadgerDB’s compaction not being able to keep up, leading to the disk filling up.

LittDB’s write latency is orders of magnitude faster than LevelDB, and approximately 4 times faster than BadgerDB. More importantly though, the write latency is stable.
Read Latency
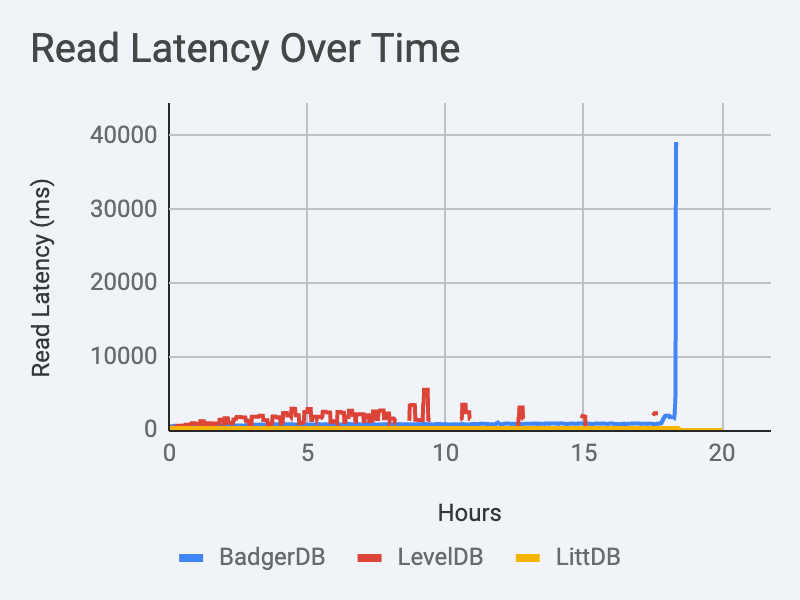

There is no way to say this kindly, LevelDB’s read time is really slow.

Although it’s a lot better than LevelDB, BadgerDB’s read latency leaves a lot to be desired.

LittDB blows away the competition when it comes to read latency. It’s not even close.
Memory Use
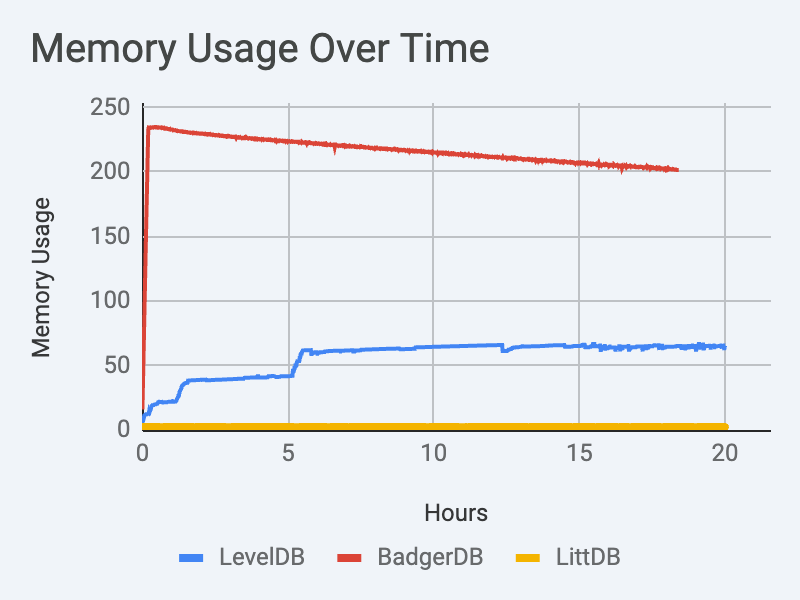

I was actually quite surprised when I saw how much memory LevelDB was using. It’s throughput is so low, and so I expected the memory footprint to be proportionally smaller. But most of this memory is being used for compaction, which is why LevelDB is so slow in the first place.

As bad as LevelDB’s memory footprint is, BadgerDB somehow manages to be much worse. The memory utilized by BadgerDB is absolutely mind blowing.

LittDB is very efficient in its use of memory. It’s important to point out that of the memory reported in the chart above, at least 1GB is being used by the benchmarking tool’s internal buffers, and is not directly related to LittDB’s use.
CPU Use
Note that for measurements of CPU usage, I do not separate usage by the database and usage by the benchmarking framework. Some fraction of the CPU utilization will be due to the benchmarking framework.

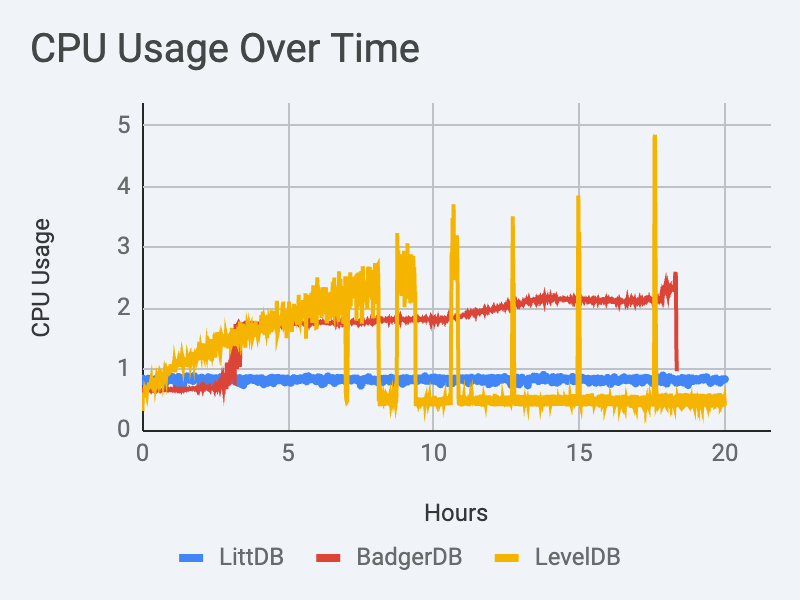
LevelDB’s use of CPU resources is alarming. It grows and grows up until the point when the DB starts thrashing on disk IO (at which point in time the DB becomes unresponsive for long periods of time).

Notice the sharp spike in CPU usage at the 4 hour mark. This is when data begins expiring, and when BadgerDB’s compaction starts having work to do. As time goes on, compaction falls further and further behind, all the while eating more and more system resources.

LittDB’s CPU usage is highly stable.
The Path Forward
Sometimes the best solution isn't the most general one. In those cases, it’s best to set aside the general purpose off the shelf solution, and to build something specifically designed to excel at a narrowly defined task.
"I fear not the man who has practiced 10,000 kicks once, but I fear the man who has practiced one kick 10,000 times." - Bruce Lee
The future of scalable blockchain infrastructure isn't built on compromises with general-purpose tools. The future will be built on purpose-designed solutions that excel at exactly what they're designed to do.
For more information about LittDB, check out the LittDB documentation on github.